爬虫入门指南-某专利网站的专利数据查询并存储
免责声明
本教程仅用于教育目的,演示如何合法获取公开专利数据。在实际操作前,请务必:
1. 仔细阅读目标网站的robots.txt文件和服务条款
2. 控制请求频率,避免对服务器造成负担
3. 仅获取和使用公开数据
4. 不用于商业用途或大规模抓取
本次教学网站:aHR0cDovL2VwdWIuY25pcGEuZ292LmNuL0FkdmFuY2Vk(请自行base64解密)。
本次实现需求:1.查询某固定日期之后的所有专利 2.将获取到的专利数据写入xlsx文件
本次使用语言:python
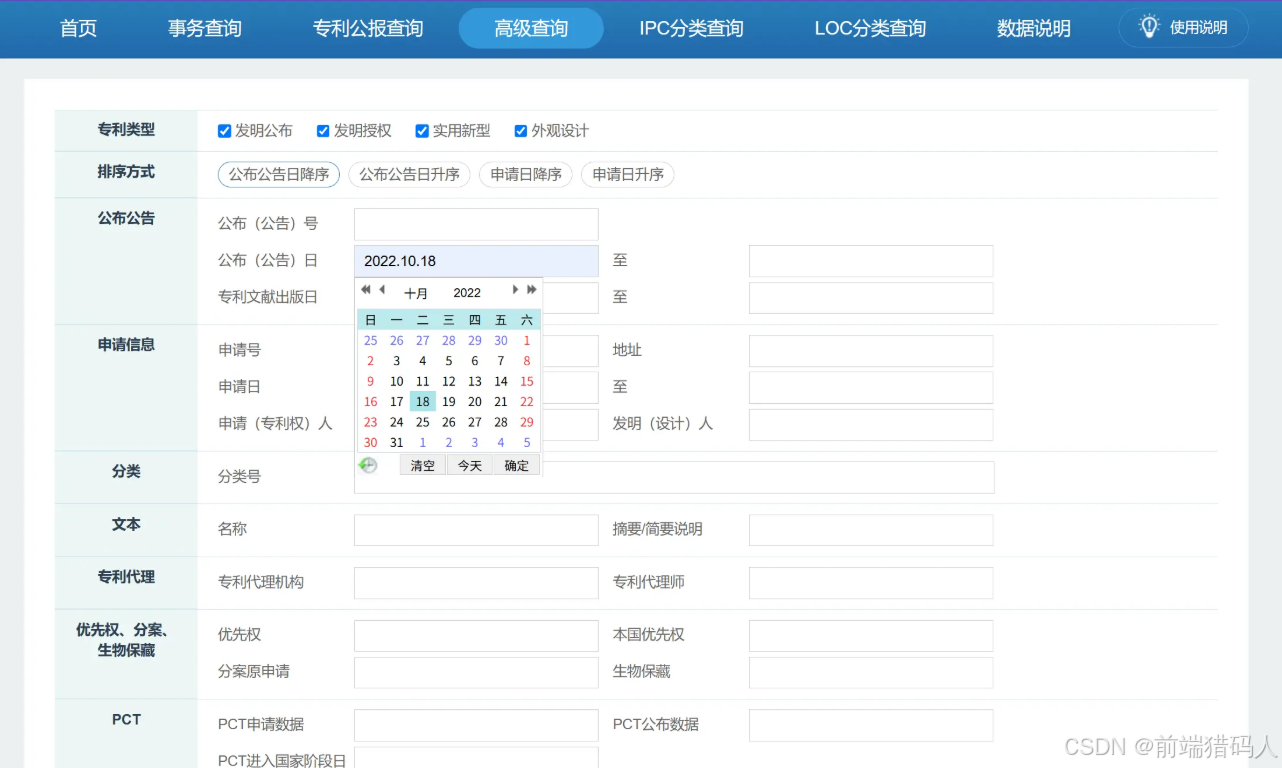
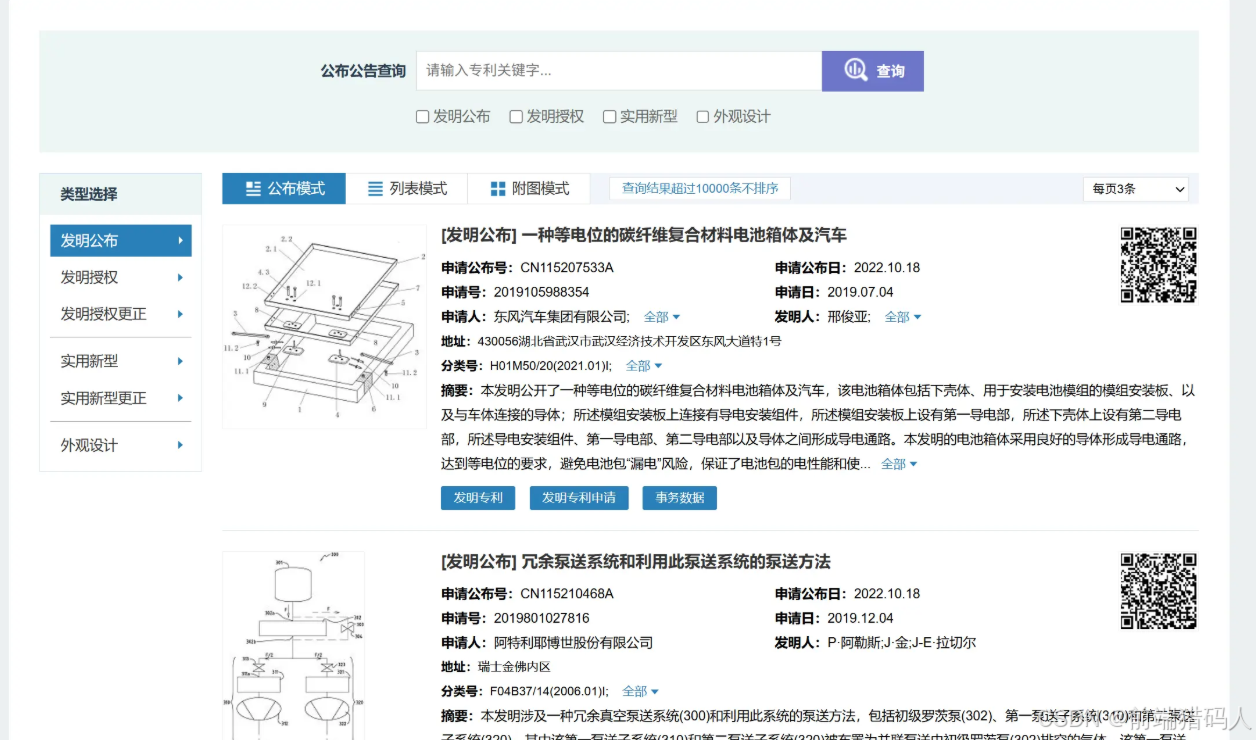
实现思路:DrissionPage实现自动化操作网页,向公布开始日期的输入框插入需要查询的日期(若需要其他查询条件思路与其基本一致),点击查询按钮跳转至专利数据列表页面,获取总计页面数量,循环总计页面数量,自动获取并向xlsx文件写入每一页数据,如果当前页不是最后一页,点击下一页继续获取数据并完成写入。


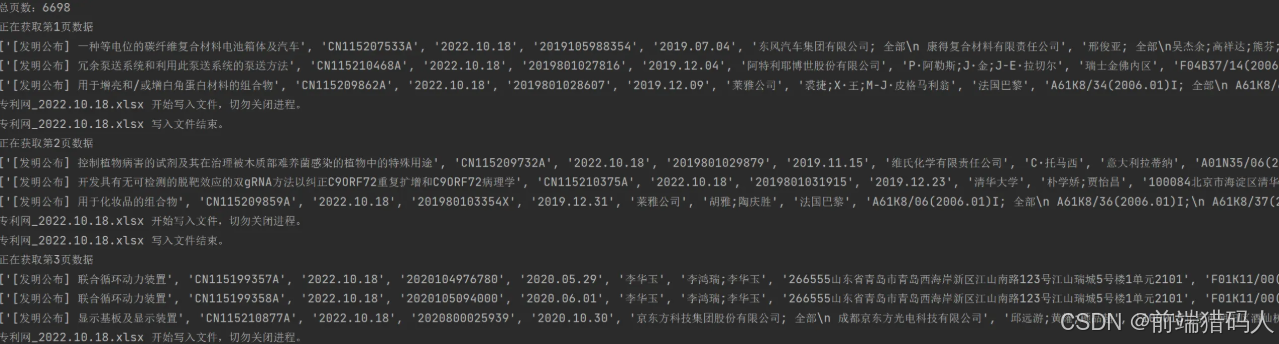
程序输出结果:
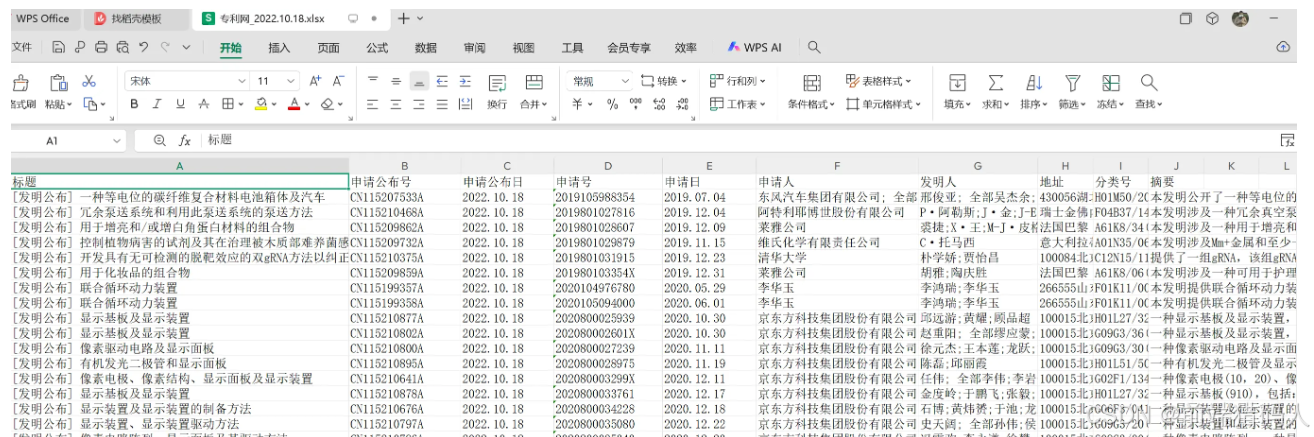
完整代码
from DrissionPage import ChromiumOptions, ChromiumPage
import re
from bs4 import BeautifulSoup
from DataRecorder import Recorderco = ChromiumOptions()
co.headless() # 无头模式
# 创建页面对象,并启动浏览器
page = ChromiumPage(co)
# 跳转到页面
page.get('http://epub.cnipa.gov.cn/Advanced')
start_date = '2022.10.18'
r = Recorder(f'专利网_{start_date}.xlsx')
r.set.head(['标题', '申请公布号', '申请公布日', '申请号', '申请日', '申请人', '发明人', '地址', '分类号', '摘要'])
r.record()def save_data(datalist):r.add_data(datalist)r.record()# 定位到开始日期文本框,获取文本框元素
ele = page.ele('#pd_begin')
# 输入对文本框输入开始日期
ele.input(start_date)
# 定位到页面文本为“查询”的按钮并点击
search_button = page.ele('.icon-sea')
search_button.click()
page.wait(5)total_element = page.ele('css:.page_total')
total_content = total_element.text
# 正则提取页数
page_num = re.search(r'共 (\d+) 页', total_content).group(1)
print(f'总页数:{page_num}') # 输出:总页数:****now_page = 1
max_page = int(page_num)
data_list = []def get_data():res = page.ele('#result')items = res.eles('css:.item')list_arr = []for item in items:title = item.ele('.title').textpublication_num = item.ele('.info').eles('tag:dd')[0].textpublication_date = item.ele('.info').eles('tag:dd')[1].textapplication_num = item.ele('.info').eles('tag:dd')[2].textapplication_date = item.ele('.info').eles('tag:dd')[3].textapplicant = item.ele('.info').eles('tag:dd')[4].textinventor = item.ele('.info').eles('tag:dd')[5].textaddress = item.eles('.intro')[0].eles('tag:dd')[0].texttype_num = item.eles('.intro')[1].eles('tag:dd')[0].textdes = item.eles('.intro')[2].eles('tag:dd')[0].textif item.eles('.intro')[2].eles('tag:dd')[0].ele('tag:p'):des_dom = item.eles('.intro')[2].eles('tag:dd')[0].ele('tag:p').htmlsoup = BeautifulSoup(des_dom, 'html.parser')for tag in soup.find_all(class_=['point', 'open j-open-alltxt']):tag.decompose()des = soup.get_text(strip=True).replace('\n', ' ')arr = [title, publication_num, publication_date, application_num, application_date, applicant, inventor,address, type_num, des]print(arr)list_arr.append(arr)save_data(list_arr)def get_page_data():if now_page == 1:get_data()else:next_button = page.ele('.next_page')page.wait(2)next_button.click()page.wait(3)get_data()for i in range(1, max_page + 1):now_page = iprint(f'正在获取第{i}页数据')get_page_data()page.quit()