Mac安装配置InfluxDB,InfluxDB快速入门,Java集成InfluxDB
1. 与MySQL的比较
| InfluxDB | MySQL | 解释 |
|---|---|---|
| Bucket | Database | 数据库 |
| Measurement | Table | 表 |
| Tag | Indexed Column | 索引列 |
| Field | Column | 普通列 |
| Point | Row | 每行数据 |
2. 安装FluxDB
brew update
默认安装 2.x的版本
brew install influxdb
查看influxdb版本
influxd version # InfluxDB 2.7.11 (git: fbf5d4ab5e) build_date: 2024-11-26T18:06:07Z
启动influxdb
influxd
访问面板
http://localhost:8086/
配置用户信息
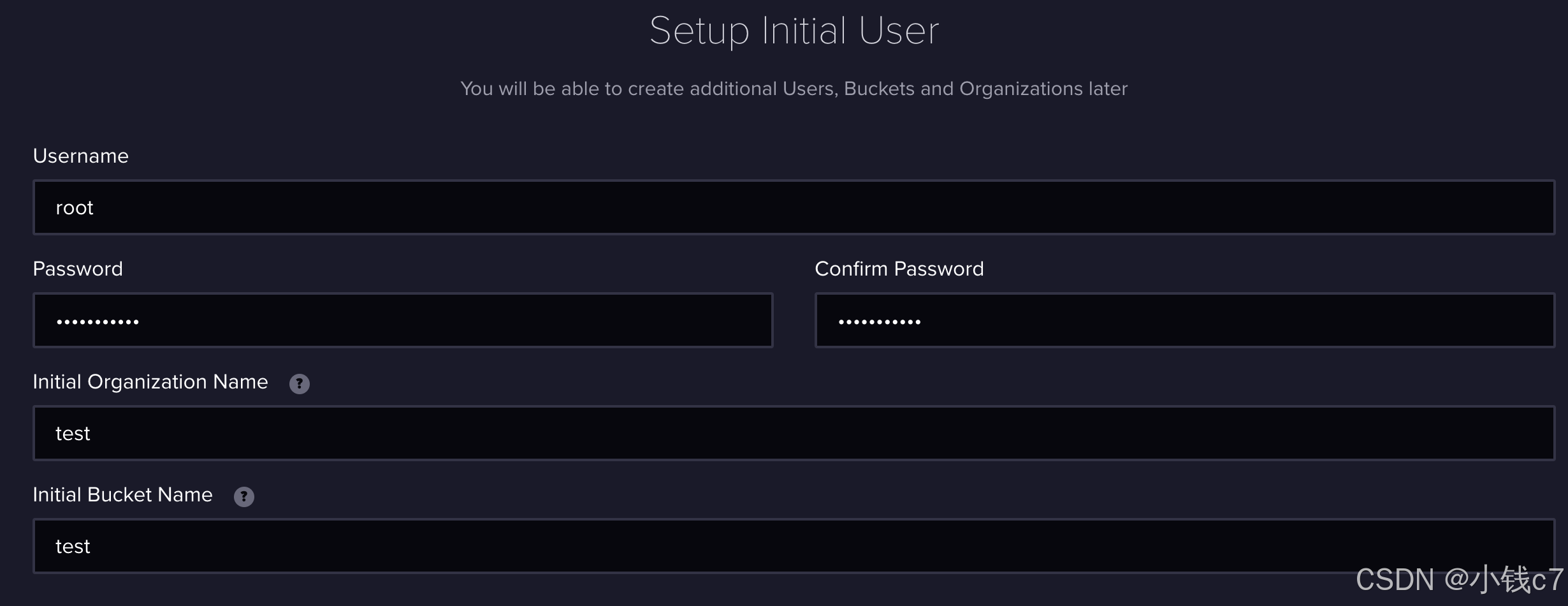
保存token
L5IeK5vutRmkCuyzbz781GVKj4fR6fKGQdl3CaWAPNEKmigrI0Yt8IlEN5_qkO9Lgb80BpcISK0U4WSkWDcqIQ==
3. 使用行协议写入数据
官网规范
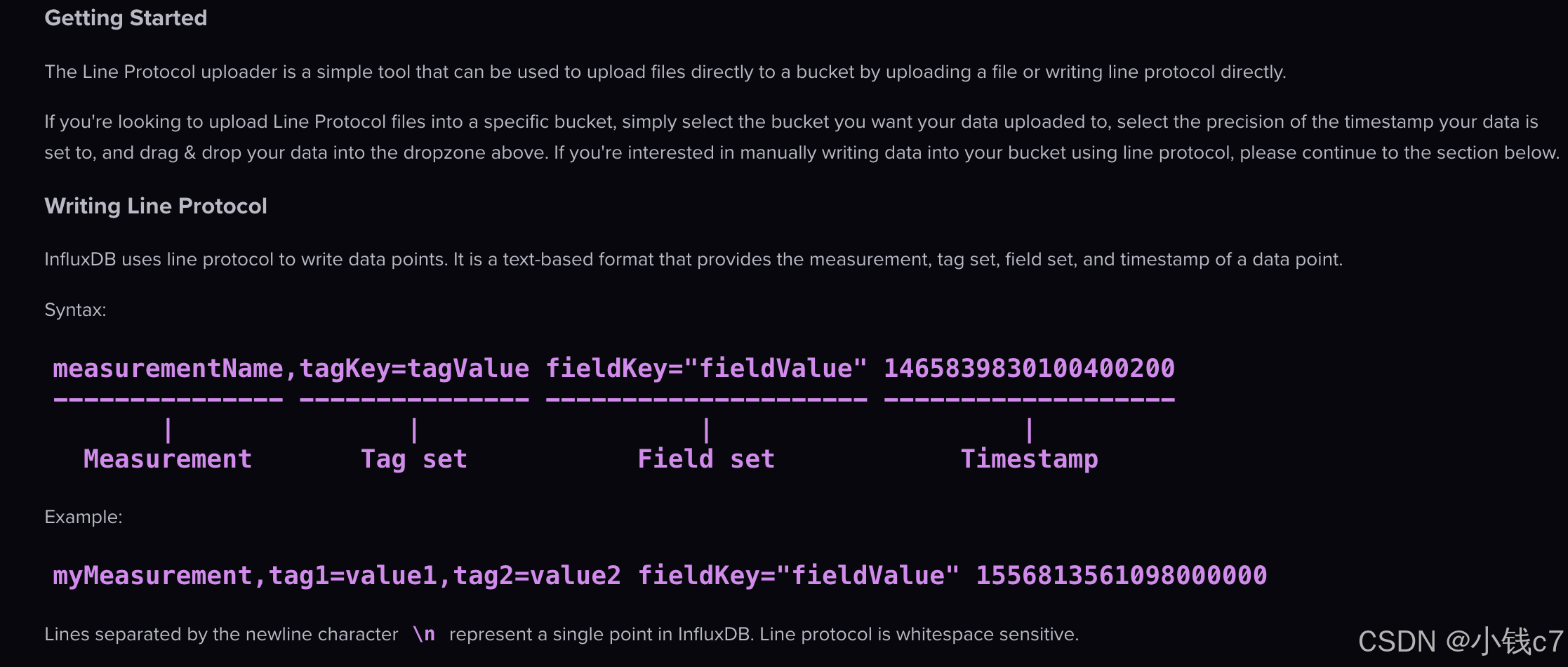
- 首先是一个
measurementName,和指定MySQL的表名一样 - 然后是
Tag,和指定MySQL的索引列一样,多个Tag通过逗号分隔 - 然后是
Field,和指定MySQL的普通列一样多个Field通过逗号分隔,与Tag通过空格分隔 - 最后是时间戳(选填,下面测试时单位为秒)
测试写入:
user,name=jack age=11 1748264631
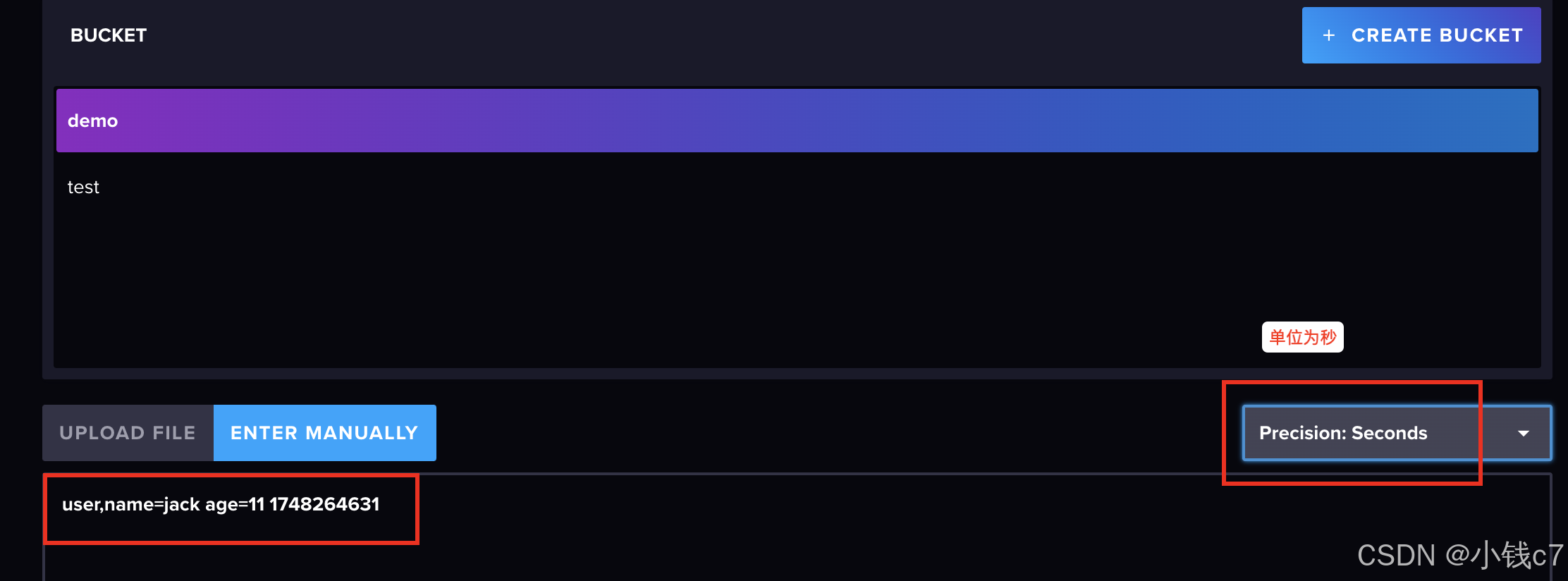
结果:
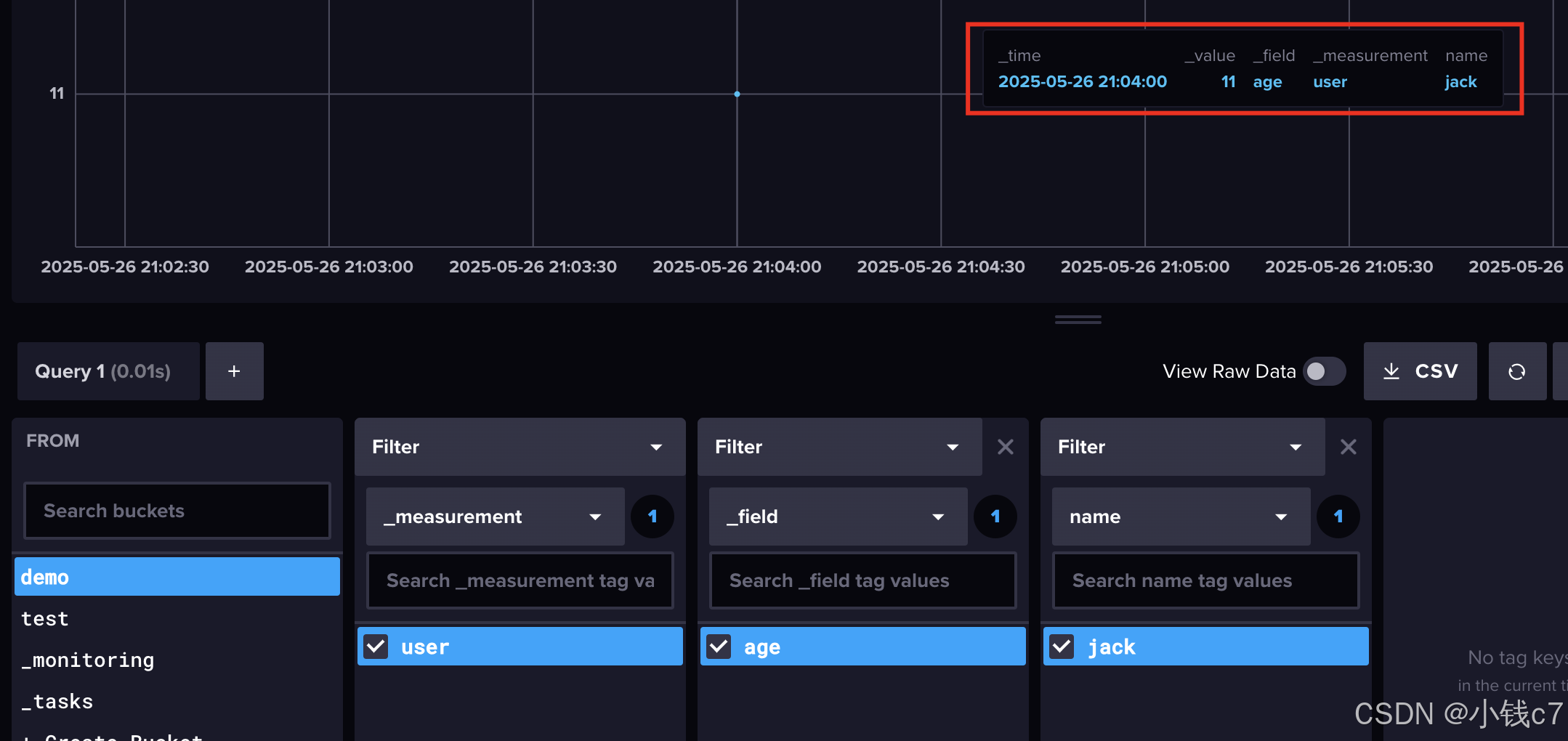
4. 使用Flux查询数据
- from:从哪个Bucket即桶中查询数据
- range:根据时间筛选数据,单位有ms毫秒,s秒,m分钟,h消失,d天,w星期,mo月,y年,比如
range(start: -1d, stop:now())就是过去一天内的数据,其中stop:now()是默认的,可以不写。 - filter:根据列筛选数据
样例并解释:
from(bucket: "demo") # 从demo这个数据库中去数据|> range(start: -1d, stop:now()) # 时间范围筛选|> filter(fn: (r) => r["_measurement"] == "user") # 从这个user这个表查询数据|> filter(fn: (r) => r["name"] == "jack") # 根据索引等值查询,相当于MySQL后面的where条件,influx会根据这个tag上的倒排索引加快查询速度|> filter(fn: (r) => r["_field"] == "age") # 相当于MySQL查询具体的列的数据,只不过有多个Field会被拆分为多行,每行对应一个Field的数据
关于r["_field"] == "age"的问题:为什么需要这么查询?因为Field如果有多个,就会被拆成多行
比如我们插入数据时是这样的:user,name=jack age=18,height=180 1716715200000000000,虽然这是一个数据点Point,但是由于有两个Field,那么查询到的数据其实是两行,如果加了r["_field"] == "age",就只会出现第一条数据,注意Tag不会被拆分为多行
| _measurement | name | _field | _value | _time |
|---|---|---|---|---|
| user | jack | age | 18 | 2024-05-26 00:00:00Z |
| user | jack | height | 180 | 2024-05-26 00:00:00Z |
5. SpringBoot集成
5.1 引入依赖
<dependency><groupId>com.influxdb</groupId><artifactId>influxdb-client-java</artifactId><version>6.9.0</version>
</dependency>
<dependency><groupId>org.jetbrains.kotlin</groupId><artifactId>kotlin-stdlib</artifactId><version>1.8.20</version>
</dependency>
5.2. 插入数据
5.2.1 基础数据
private final static String token = "L5IeK5vutRmkCuyzbz781GVKj4fR6fKGQdl3CaWAPNEKmigrI0Yt8IlEN5_qkO9Lgb80BpcISK0U4WSkWDcqIQ==";
private final static String org = "test";
private final static String bucket = "demo";
private final static String url = "http://127.0.0.1:8086";
5.2.2 通过行协议插入
private static void writeDataByLine() {InfluxDBClient influxDBClient = InfluxDBClientFactory.create(url, token.toCharArray());WriteApiBlocking writeApi = influxDBClient.getWriteApiBlocking();String data = "user,name=tom age=18 1748270504";writeApi.writeRecord(bucket, org, WritePrecision.S, data);
}
5.2.3 通过Point插入
private static void writeDataByPoint() {InfluxDBClient influxDBClient = InfluxDBClientFactory.create(url, token.toCharArray());WriteApiBlocking writeApi = influxDBClient.getWriteApiBlocking();Point point = Point.measurement("user").addTag("name", "jerry").addField("age", 20f).time(Instant.now(), WritePrecision.S);writeApi.writePoint(bucket, org, point);
}
5.2.4 通过Pojo类插入
import com.influxdb.annotations.Column;
import com.influxdb.annotations.Measurement;
import lombok.AllArgsConstructor;
import lombok.NoArgsConstructor;import java.time.Instant;@Measurement(name = "user")
@NoArgsConstructor
@AllArgsConstructor
public class InfluxData {@Column(tag = true)String name;@ColumnFloat age;@Column(timestamp = true)Instant time;
}
private static void writeDataByPojo() {InfluxDBClient influxDBClient = InfluxDBClientFactory.create(url, token.toCharArray());WriteApiBlocking writeApi = influxDBClient.getWriteApiBlocking();InfluxData influxData = new InfluxData("cat", 30f, Instant.now());writeApi.writeMeasurement(bucket, org, WritePrecision.S, influxData);
}
5.3 查询数据
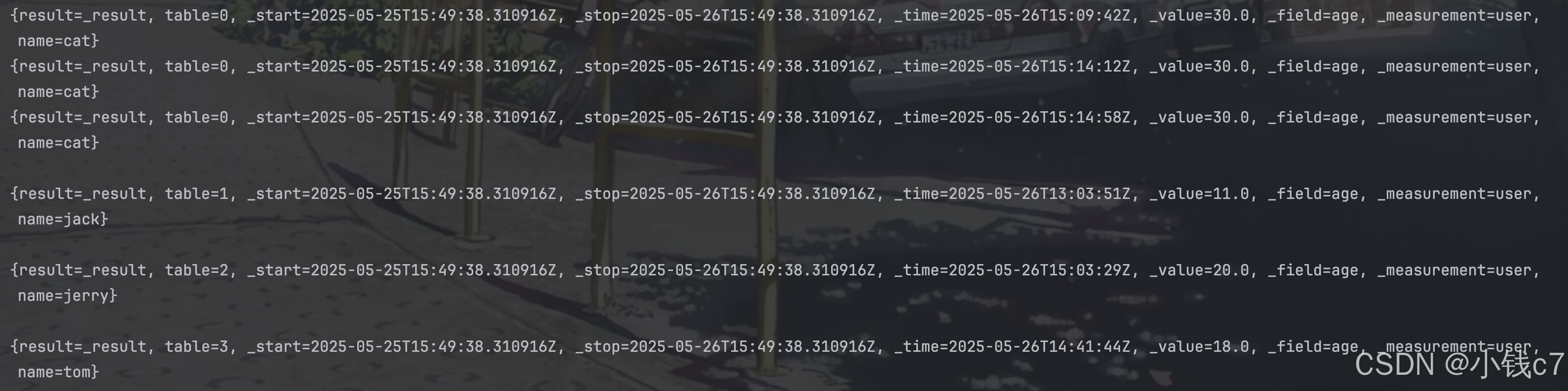
private static void queryData() {InfluxDBClient influxDBClient = InfluxDBClientFactory.create(url, token.toCharArray());String query = "from(bucket: \"demo\")\n" +" |> range(start: -1d, stop:now())\n" +" |> filter(fn: (r) => r[\"_measurement\"] == \"user\")";List<FluxTable> fluxTables = influxDBClient.getQueryApi().query(query, org);for (FluxTable fluxTable : fluxTables) {// 根据索引列分组for (FluxRecord record : fluxTable.getRecords()) { // 每组的数据System.out.println(record.getValues());}System.out.println();}
}
最终结果:
5.4 查询升级
自定义查询参数,时间范围查询
@Data
public class InfluxDataQuery {private String plcName;@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")private LocalDateTime startTime;@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")private LocalDateTime stopTime;private String topic;
}
public List<Map<String, Object>> queryData(InfluxDataQuery queryParams) {String plcName = queryParams.getPlcName();LocalDateTime startTime = queryParams.getStartTime(), stopTime = queryParams.getStopTime();String topic = queryParams.getTopic();if (startTime == null) {throw new RuntimeException("startTime不能为空");}InfluxDBClient influxDBClient = InfluxDBClientFactory.create(url, token.toCharArray());StringBuilder sb = new StringBuilder();sb.append("\nfrom(bucket: \"").append(bucket).append("\")\n");if (stopTime == null) {stopTime = LocalDateTime.now();}sb.append(" |> range(start:").append(startTime.atOffset(ZoneOffset.UTC).format(DateTimeFormatter.ISO_OFFSET_DATE_TIME)).append(",stop:").append(stopTime.atOffset(ZoneOffset.UTC).format(DateTimeFormatter.ISO_OFFSET_DATE_TIME)).append(")\n");if (StringUtils.hasText(plcName)) {sb.append(" |> filter(fn: (r) => r[\"plcName\"] == \"").append(plcName).append("\")\n");}if (StringUtils.hasText(topic)) {sb.append(" |> filter(fn: (r) => r[\"_measurement\"] == \"").append(topic).append("\")\n");}log.info("query: {}", sb);List<FluxTable> fluxTables = influxDBClient.getQueryApi().query(sb.toString(), org);List<Map<String, Object>> dataList = new ArrayList<>();for (FluxTable fluxTable : fluxTables) {// 根据索引列分组for (FluxRecord record : fluxTable.getRecords()) { // 每组的数据dataList.add(record.getValues());}}return dataList;
}
拼接好的SQL大概长这样子:
