电商平台 API、数据抓取与爬虫技术的区别及优势分析
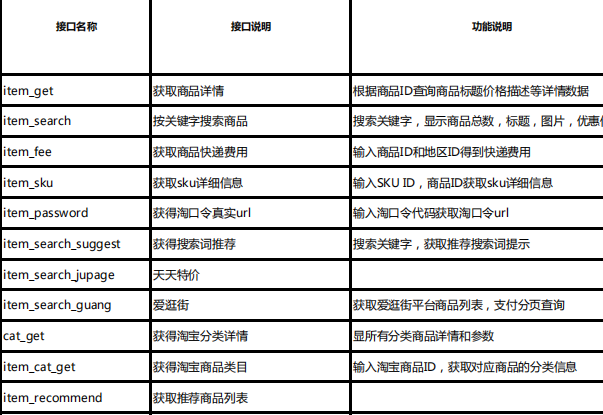
一、技术定义与核心原理
-
电商平台 API(应用程序编程接口)
作为平台官方提供的标准化数据交互通道,API 通过 HTTP 协议实现不同系统间的结构化数据传输。开发者需申请授权(如 API 密钥),按照文档规范调用接口获取商品信息、订单数据等资源。例如,亚马逊 MWS API 允许卖家实时同步库存和订单状态,京东 API 支持商品搜索和用户行为分析。其核心优势在于合法性和稳定性,数据格式明确(如 JSON/XML),且平台提供持续维护。 -
数据抓取
泛指通过技术手段从网页或系统中获取数据的行为,包括API 调用和爬虫技术。广义上的数据抓取需根据场景选择工具:小规模数据可手动复制粘贴,大规模需求则依赖自动化方案。例如,某服装品牌通过 API 整合多平台库存,或使用爬虫监控竞品价格波动。 -
爬虫技术
特指通过编写程序模拟浏览器行为,自动遍历网页并提取数据的技术。典型工具如 Scrapy、Octoparse,可处理动态加载内容(如 JavaScript 渲染页面),并支持代理 IP 和验证码识别。其核心特点是灵活性,能突破 API 限制获取非结构化数据(如用户评论、页面布局),但需应对反爬机制(如 IP 封禁、滑块验证)。
二、核心区别与关键特征
| 维度 | 电商平台 API | 数据抓取(含 API) | 爬虫技术 |
|---|---|---|---|
| 数据来源 | 平台官方接口,结构化数据 | 混合(API + 网页),半结构化 / 非结构化数据 | 网页内容,非结构化数据 |
| 合法性 | 合法(需授权) | 部分合法(API 合法,爬虫可能违规) | 高风险(可能违反平台协议或法律) |
| 稳定性 | 高(平台维护) | 中(依赖平台更新) | 低(反爬措施易导致失效) |
| 技术门槛 | 中(需理解接口文档) | 低 - 高(手动采集简单,爬虫开发复杂) | 高(需编程和反爬策略) |
| 成本 | 中(调用费用 + 开发成本) | 低 - 高(手动低成本,爬虫需维护代理等) | 高(反爬工具、IP 池等) |
| 数据范围 | 受限(平台开放字段) | 灵活(可覆盖 API 和网页) | 全面(可抓取页面所有可见内容) |
三、优势对比与应用场景
-
电商平台 API 的核心优势
- 合法合规:避免法律风险,如淘宝 API 需企业认证,数据使用受平台条款约束。
- 高效稳定:接口响应速度快,支持批量请求和缓存策略,适合大规模数据同步(如订单处理)。
- 功能丰富:集成平台核心能力,如京东 API 提供用户画像分析,拼多多 API 支持社交裂变推广。
- 案例:某独立站通过 Shopify API 实现库存自动化管理,库存周转率提升 30%。
-
数据抓取的灵活适配
- 混合策略:结合 API 获取基础数据(如商品 ID),爬虫补充详情页信息(如用户评论)。
- 低成本验证:小规模需求可先用爬虫测试数据价值,再决定是否接入 API。
- 案例:某创业公司通过爬虫分析竞品页面布局,优化自有平台 UI 设计,用户转化率提升 15%。
-
爬虫技术的不可替代性
- 非结构化数据获取:抓取用户生成内容(UGC)、动态图表等 API 未开放的数据。
- 跨平台整合:同时采集多个电商平台数据(如亚马逊、eBay),实现全局市场分析。
- 案例:某市场调研公司使用爬虫监控全球 30 个电商平台的价格趋势,为客户提供定价策略建议。
四、风险与挑战
-
法律风险
- 爬虫可能违反《反不正当竞争法》(中国)或《计算机欺诈与滥用法案》(美国),如 HiQ Labs 因爬取 LinkedIn 公开数据引发五年诉讼。
- 案例:成都某公司因爬虫非法控制 58 台计算机系统,负责人获刑 8 个月。
-
技术挑战
- 反爬机制:动态加载、设备指纹、验证码等技术增加爬虫开发难度。
- API 限制:平台可能调整接口字段或增加调用频率限制(如淘宝 API 普通开发者日调用量≤1 万次)。
-
成本权衡
- API 隐性成本高:开发团队月均投入 3-5 万元,维护费用年均 1-3 万元。
- 爬虫需持续投入:代理 IP、验证码识别服务等年成本可达数万元。
五、技术发展趋势
-
API 生态优化
- 低代码工具普及:Zapier、集乘云等平台降低 API 集成门槛,中小企业月费低至 100 元。
- 智能化增强:AI 驱动的 API 管理工具(如 AWS API Gateway)支持自动异常检测和流量调控。
-
爬虫技术升级
- AI 大模型赋能:DeepSeek R1 等模型可自动生成反反爬代码,识别复杂验证码。
- 分布式架构:结合 Crawlera 代理池和 Scrapy 框架,实现高并发、低风险的数据采集。
-
反爬技术迭代
- 动态风控:B 站通过设备指纹和实时流量分析,拦截 90% 以上的恶意爬虫。
- 法律协同:平台与执法机构合作打击非法爬虫,2025 年全球爬虫攻击量同比下降 15%。
六、决策建议与最佳实践
-
技术选型原则
- 合规优先:涉及用户数据或商业竞争时,优先选择 API。
- 成本可控:小规模需求用爬虫验证,大规模业务接入 API。
- 混合策略:API + 爬虫结合,平衡效率与数据完整性。
-
风险规避策略
- API 合规:签订数据使用协议,明确责任划分(如数据泄露赔偿条款)。
- 爬虫伦理:遵守 robots.txt 协议,控制请求频率,避免干扰平台运营。
-
未来趋势适配
- 关注 API 开放动态:拼多多等平台逐步开放更多接口,降低企业接入成本。
- 投资 AI 工具:利用 InsCode AI IDE 等智能化开发环境,提升爬虫效率和稳定性。
七、结论
电商平台 API、数据抓取与爬虫技术在电商数据生态中各有其不可替代的价值。API 以合法性和稳定性见长,适合大规模结构化数据交互;爬虫技术凭借灵活性和数据全面性,在非结构化数据采集领域占据优势;数据抓取则是两者的有机结合,需根据业务需求动态调整策略。企业应在合规框架内,综合评估成本、效率与风险,构建可持续的数据获取体系。未来,随着 AI 和边缘计算的发展,三者将进一步融合,推动电商行业从 “数据驱动” 向 “智能决策” 演进。