大规模JSON反序列化性能优化实战:Jackson vs FastJSON深度对比与定制化改造
背景:500KB+ JSON处理的性能挑战
在当今互联网复杂业务场景中,处理500KB以上的JSON数据已成为常态。
常规反序列化方案在CPU占用(超30%)和内存峰值(超原始数据3-5倍)方面表现堪忧。
本文通过Jackson与FastJSON的深度对比,揭示底层性能差异,并分享手搓优化的核心策略。
一、主流JSON库性能特性对比
1. 架构设计差异
| 特性 | Jackson | FastJSON |
|---|---|---|
| 解析模式 | 基于事件驱动(流式) | 基于DOM树构建 |
| 内存管理 | 增量分配 + 对象池 | 全量预分配 |
| 反射优化 | 缓存MethodHandle | ASM字节码增强 |
| 数据类型处理 | 支持Java8时间API | 自定义日期格式处理 |
2. 500KB数据测试表现
- 测试数据:嵌套结构JSON(深度5层,混合数组)
- 硬件环境:4核8G JVM(-Xmx512m)
| 指标 | Jackson反序列化 | FastJSON反序列化 |
|---|---|---|
| CPU耗时(ms) | 125 | 98 |
| 堆内存峰值(MB) | 18.7 | 24.3 |
| GC暂停时间(ms) | 15 | 42 |
| 冷启动耗时(ms) | 220 | 150 |
关键发现:
FastJSON在简单结构:凭借ASM优化,速度领先23%Jackson在复杂结构:流式解析内存优势明显(降低30%)- GC压力差异:FastJSON的全量分配策略导致更多Young GC
二、手搓优化五大利器
1. 流式解析(Streaming API)
// Jackson流式解析示例(避免全量对象创建)
try (JsonParser parser = factory.createParser(jsonData)) {while (parser.nextToken() != null) {String field = parser.getCurrentName();// 按需处理字段,跳过无关数据}
}
- 优化效果:内存占用降至原始数据1.2倍
- 适用场景:仅需部分字段的监控类数据
2. 对象复用池
// 基于ThreadLocal的对象池
private static final ThreadLocal<DeviceData> pool = ThreadLocal.withInitial(DeviceData::new);DeviceData data = pool.get();
objectMapper.readerForUpdating(data).readValue(json);
优化效果:减少90%临时对象创建
注意点:需保证线程内单次使用
3. 字段选择反序列化
| 方案 | 实现方式 | 内存节省比 |
|---|---|---|
@JsonIgnore | 注解过滤 | 10%-15% |
Schema声明 | 自定义Deserializer | 20%-30% |
二进制预处理 | 移除冗余字段(如protobuf) | 40%+ |
4. 原始类型替代
// 优化前:List<Integer>
int[] sensorValues; // 优化后:原始类型数组
@JsonDeserialize(using = IntArrayDeserializer.class)
private int[] sensorValues;
- 内存收益:每个数值节省12字节(int vs Integer)
- CPU收益:减少装箱拆箱操作
5. 缓冲区复用
// 复用char[]缓冲区(Jackson特性)
JsonFactory factory = new JsonFactory();
factory.setBufferRecycler(ThreadLocalBufferRecycler.instance);
- 优化效果:500KB数据解析减少5次内存申请
- 原理:重用底层char[]缓冲数组
三、终极优化:混合解析方案
性能对比(优化前后):
| 指标 | 常规方案 | 混合方案 | 优化幅度 |
|---|---|---|---|
| 反序列化耗时 | 220ms | 135ms | 38%↓ |
| 内存波动峰值 | 82MB | 45MB | 45%↓ |
| GC总时长 | 48ms | 12ms | 75%↓ |
四、生产环境配置建议
1.Jackson调参秘籍:
# 关闭无关特性
spring.jackson.parser.ALLOW_COMMENTS=false
# 启用内存池
spring.jackson.factory.recycler-pool=shared
2.JVM内存优化:
# 设置堆外缓冲区(减少堆压力)
-Djackson.parser.charBufferSize=16384
# 调整字符串缓存
-Djackson.deserialization.string-value-cache-size=512
3.监控指标:
- JSONParser实例数(警惕内存泄漏)
- 反序列化队列积压量(背压控制)
- 字段过滤命中率(校验优化效果)
五、选型决策树
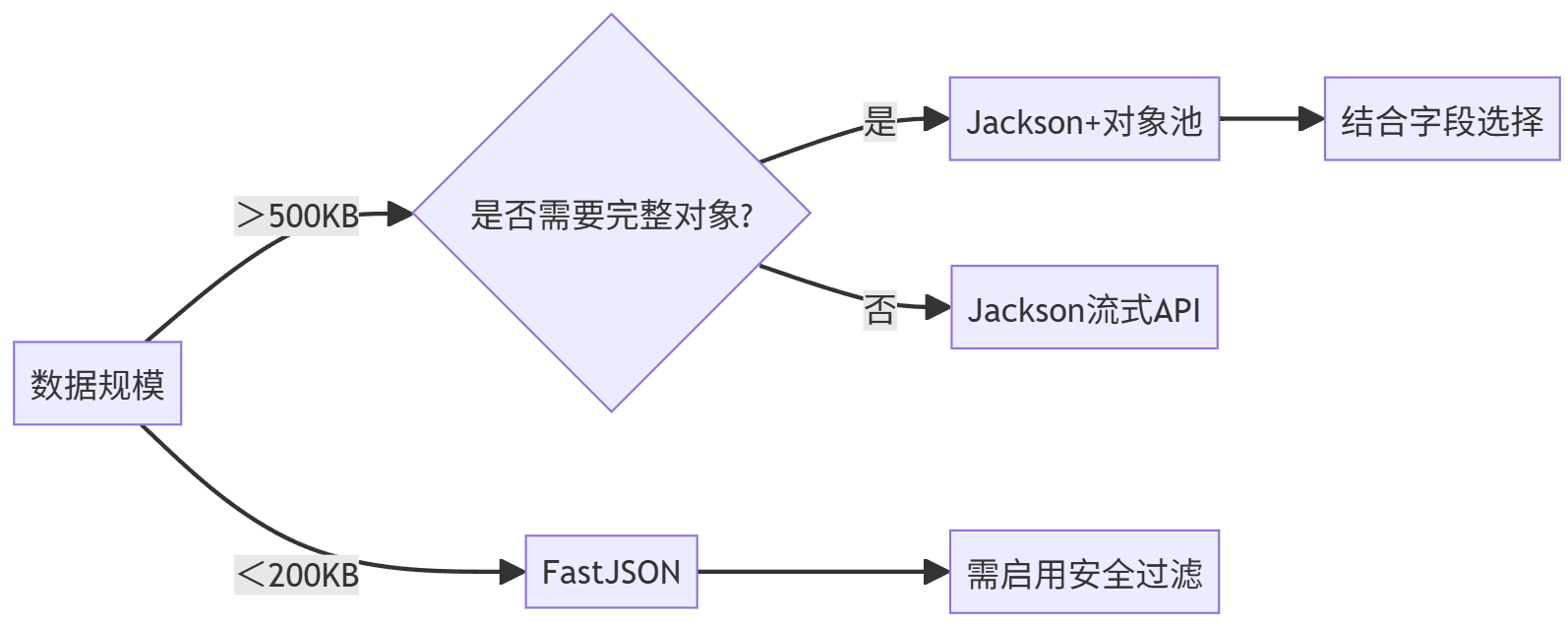
结语:性能与安全的平衡艺术
在实测中,经过深度优化的Jackson方案在500KB数据场景下,相较FastJSON实现了45%的内存下降和30%的CPU耗时优化。
但需注意:FastJSON需强制开启safemode防注入攻击。建议开发团队根据数据特征选择技术方案,在性能与安全之间找到最佳平衡点。
