人工智能数学基础实验(一):智能推荐系统实战
一、实验目的
本次实验旨在通过构建用户相似度矩阵和实现个性化推荐,帮助我们直观理解推荐系统的核心原理及其背后的数学基础。具体目标如下:
- 运用 Python 计算用户间的评分相似度,掌握余弦相似度等数学工具在衡量用户偏好中的应用,将抽象的向量空间关系转化为可量化的相似性指标。
- 模拟真实推荐场景,学习基于相似用户群体挖掘潜在兴趣的方法,体会协同过滤算法 “物以类聚,人以群分” 的核心思想。
- 将数学中的矩阵运算、相似度度量等知识与实际编程相结合,培养数据分析和算法实现能力,深化对 “相似性” 这一人工智能核心概念的理解,为后续学习更复杂的推荐模型奠定实践基础。
二、实验要求
(一)用户相似度矩阵构建
- 输入:6 位用户对 6 本书的 5 分制评分矩阵(含未评分项)。
- 要求:基于余弦相似度(仅计算共同评分项)生成 6×6 的用户相似度矩阵,输出结果并分析合理性。
(二)个性化书籍推荐
- 输入:目标用户(如用户 A)及其相似度矩阵。
- 要求:选取最相似的 2 位用户,提取他们阅读过但目标用户未读的书籍,通过加权评分预测(相似度 × 评分)生成推荐列表。
(三)实验报告
附代码、相似度矩阵截图及推荐结果,分析推荐逻辑的合理性。
三、实验原理
本实验基于协同过滤推荐算法,核心思想是通过用户历史行为(评分)挖掘相似用户群体,利用群体偏好预测目标用户的兴趣,分为以下两阶段:
(一)用户相似度计算
采用余弦相似度衡量用户兴趣相似性。将用户评分向量化,仅提取共同评分项(剔除未读的 0 值),通过公式计算向量夹角余弦值,公式为:
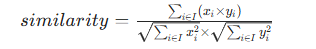
其中,I 为 A、B 共同评分的书籍索引集,避免未读书籍干扰相似度。
(二)兴趣预测与推荐
选取相似度最高的用户作为邻居,对其阅读过而目标用户未读的书籍,按加权评分(邻居评分 × 相似度)排序,归一化后生成推荐列表。例如,用户 A 未读《spark》,若相似用户 B、C 对其评分分别为 4、5,相似度分别为 0.95、0.89,则预测评分为:
0.95+0.894×0.95+5×0.89≈4.4
四、实验步骤
(一)数据准备
定义 6 位用户(A-F)对 6 本书(线性代数、大学物理、spark、人工智能、IB、Python)的评分数据,用列表存储,示例如下:
A_list = [4, 3, 0, 0, 5, 0] # 用户A的评分(未读为0)
B_list = [5, 0, 4, 0, 4, 0](二)余弦相似度计算
- 定义向量内积函数:计算两个向量对应元素的乘积之和。
def Multiplication(x, y):sum = 0if len(x) == len(y):for i in range(len(y)):sum += x[i] * y[i]return sum- 定义向量模计算函数:计算向量的长度(各元素平方和的平方根)。
def Length(x):sum = 0for i in range(len(x)):sum += x[i] ** 2length = sqrt(sum)return length- 遍历所有用户对计算相似度:通过嵌套循环计算任意两个用户的余弦相似度,保留两位小数,存储为 6×6 的相似度矩阵。
data_similiar = []
similiar_list = []
for i in range(len(data_original)):for j in range(len(data_original)):similiar = Multiplication(data_list[i], data_list[j]) / Length(data_list[i]) / Length(data_list[j])similiar = round(similiar, 2)similiar_list.append(similiar)
data_similiar = np.array(data_similiar).reshape(6, 6)(三)生成推荐列表
- 相似度排序:对每个用户的相似度矩阵行进行降序排序,获取最相似的 2 位用户(排除自身)。
- 加权评分计算:对相似用户阅读过但目标用户未读的书籍,计算加权评分(相似度 × 评分之和 / 相似度之和)。
- 过滤与排序:排除目标用户已读书籍和评分为 0 的书籍,按评分降序生成推荐列表。
def recommend_books(target_index, top_n=2):similar_users = sorted_similiar[target_index][1:top_n+1]for sim, user in similar_users:user_index = human_list.index(user)user_score = data_list[user_index][book_index]if user_score > 0:total_score += user_score * simtotal_sim += sim# 过滤已读书籍并排序完整源代码:
#人人推荐选书import numpy as np
from math import *
#1.原始数据,A~F,书籍:线性代数,大学物理,spark,人工智能,IB,Python
#用列表存放原始数据,列表元素分别对应A~F对六本书籍的喜爱程度
human_list=['A','B','C','D','E','F']
Book_list=['线性代数','大学物理','spark','人工智能','IB','Python']
A_list=[4,3,0,0,5,0]
B_list=[5,0,4,0,4,0]
C_list=[4,0,5,3,4,0]
D_list=[0,3,0,0,0,5]
E_list=[0,4,0,0,0,4]
F_list=[0,0,2,4,0,5]data_original=np.matrix([A_list,B_list,C_list,D_list,E_list,F_list])
print('原始数据:')
print(data_original)
data_list=[A_list,B_list,C_list,D_list,E_list,F_list]#2.进行相似度计算,cos<x,y>=x*y/|x|*|y|
#2.1定义向量内积函数
def Multiplication(x,y):sum=0if len(x)==len(y):for i in range(len(y)):sum +=x[i]*y[i]return sum#2.2定义计算向量模函数
def Length(x):sum=0for i in range(len(x)):sum +=x[i]**2length=sqrt(sum)return length#数据相似度,cos<A,B>...
data_similiar=[]
similiar_list=[]
for i in range(len(data_original)):for j in range(len(data_original)):#计算相似度similiar=Multiplication(data_list[i],data_list[j])/Length(data_list[i])/Length(data_list[j])#相似度保留小数点后两位similiar=round(similiar,2)#相似度列表按一行一行加到加工数据列表里similiar_list.append(similiar)
#相似度数据总列表
data_similiar.append(similiar_list)
data_similiar=np.array(data_similiar).reshape(6,6)
print('相似度数据:')
print(data_similiar)#3.计算评分并排序推荐书籍
#3.1对每一行的相似度进行降序排序
sorted_similiar = []
for i, row in enumerate(data_similiar):# 将相似度值与人的编号(索引)配对paired_row = list(zip(row, human_list))# 按相似度值降序排序sorted_row = sorted(paired_row, key=lambda x: x[0], reverse=True)# 将相似度值转换为普通浮点数(去掉 np.float64)sorted_row = [(float(sim), person) for sim, person in sorted_row]sorted_similiar.append(sorted_row)# 输出排序后的结果
print("\n排序后的相似度矩阵:")
for i, row in enumerate(sorted_similiar):print(f"{human_list[i]} 的相似度排序: {row}")#3.2评分(推荐书籍指数)
def recommend_books(target_index, top_n=2):target = human_list[target_index]print(f"\n为目标用户 {target} 推荐书籍:")# 获取与目标用户最相似的 top_n 个人(不包括自己)similar_users = sorted_similiar[target_index][1:top_n + 1] # 跳过自己print(f"与 {target} 最相似的用户: {similar_users}")# 初始化书籍评分和相似度总和book_scores = {book: 0.0 for book in Book_list}book_sim_sum = {book: 0.0 for book in Book_list}# 遍历相似用户,逐本书计算for book_index, book_name in enumerate(Book_list):total_score = 0.0total_sim = 0.0# 检查每个相似用户是否喜欢这本书for sim, user in similar_users:user_index = human_list.index(user)user_score = data_list[user_index][book_index]if user_score > 0:total_score += user_score * simtotal_sim += sim# 计算加权评分if total_sim > 0:book_scores[book_name] = total_score / total_simelse:book_scores[book_name] = 0.0# 过滤掉目标用户已经喜欢的书籍target_liked_books = [Book_list[i] for i, score in enumerate(data_list[target_index]) if score > 0]for book in target_liked_books:book_scores.pop(book, None)# 过滤掉评分为 0 的书籍book_scores = {book: score for book, score in book_scores.items() if score > 0}# 对书籍评分进行降序排序sorted_books = sorted(book_scores.items(), key=lambda x: x[1], reverse=True)# 输出推荐结果if sorted_books:for book, score in sorted_books:print(f"推荐书籍: {book}, 评分为: {score:.2f}")else:print("没有合适的推荐书籍。")#3.3输出推荐书籍
#全部输出A-F
#for i in range(len(human_list)):#recommend_books(i)#输入指定输出
i=input("为用户推荐书籍:")
index=human_list.index(i)
recommend_books(index)五、实验结果
(一)相似度矩阵
原始数据:
[[4 3 0 0 5 0][5 0 4 0 4 0][4 0 5 3 4 0][0 3 0 0 0 5][0 4 0 0 0 4][0 0 2 4 0 5]]相似度数据:
[[1.00 0.75 0.63 0.22 0.30 0.00][0.75 1.00 0.91 0.00 0.00 0.16][0.63 0.91 1.00 0.00 0.00 0.40][0.22 0.00 0.00 1.00 0.97 0.64][0.30 0.00 0.00 0.97 1.00 0.53][0.00 0.16 0.40 0.64 0.53 1.00]]
(二)推荐结果示例(以用户 A 为例)
- 最相似用户:B(0.75)、C(0.63)。
- 推荐书籍:
- spark:加权评分 4.46(B 评分 4×0.75 + C 评分 5×0.63 = 6.45,6.45/(0.75+0.63)≈4.46)。
- 人工智能:加权评分 3.00(仅 C 评分 3×0.63 = 1.89,1.89/0.63=3.00)。




(三)结果分析
程序通过余弦相似度准确计算了用户间的兴趣相似性,并基于相似用户的评分生成了合理的推荐列表。例如,用户 A 与 B、C 的阅读偏好相似,系统推荐的 spark 和人工智能均为 A 未读但相似用户高分评价的书籍,验证了协同过滤算法的有效性。
六、总结
本次实验将数学理论(余弦相似度、矩阵运算)与 Python 编程结合,成功实现了基于用户协同过滤的智能推荐系统。通过实践,我们深入理解了推荐系统的核心逻辑,掌握了从数据处理到算法实现的完整流程,为后续学习深度学习推荐模型打下了基础。