FastAPI 支持文件下载
FastAPI 支持文件下载
FastAPI 支持文件上传
Python 获取文件类型 mimetype
文章目录
- 1. 服务端处理
- 1.1. 下载小文件
- 1.2. 下载大文件(yield 支持预览的)
- 1.3. 下载大文件(bytes)
- 1.4. 提供静态文件服务
- 2. 客户端处理
- 2.1. 普通下载
- 2.2. 分块下载
- 2.3. 显示进度条下载
- 2.4. 带有断点续传的下载
- 2.5. 带有超时和重试的下载
- 2.6. 完整的下载器实现
- 3. 异常处理
- 3.1. 中文文件名错误
- 3.2. 使用 mimetypes.guess_type
- 3.3. 使用 VUE Blob 下载乱码问题
参考:
https://blog.csdn.net/weixin_42502089/article/details/147689236
https://www.cnblogs.com/bitterteaer/p/17581746.html
修改下载缓冲区大小
https://ask.csdn.net/questions/8328950
对于文件下载,FastAPI 提供了 FileResponse 和 StreamingResponse 两种方式。 FileResponse 适合小文件,而 StreamingResponse 适合大文件,因为它可以分块返回文件内容。
1. 服务端处理
1.1. 下载小文件
使用 FileResponse 可以直接下载文件,而无需在内存中加载整个文件。
"""
fastapi + request 上传和下载功能
"""
from fastapi import FastAPI, UploadFile
from fastapi.responses import FileResponse
import uvicornapp = FastAPI()# filename 下载时设置的文件名
@app.get("/download/small/{filename}")
async def download_small_file(filename: str):print(filename)file_path = "./测试任务.pdf"return FileResponse(file_path, filename=filename, media_type="application/octet-stream")if __name__ == '__main__':uvicorn.run(app, port=8000)
保证当前目录下有名为“测试任务.pdf”的文件。
然后使用浏览器下载:
http://127.0.0.1:8000/download/small/ceshi.pdf

1.2. 下载大文件(yield 支持预览的)
使用 StreamingResponse 可以分块下载文件,这样不会占用太多服务器资源,特别适用于大文件的下载。
from fastapi.responses import StreamingResponse
from fastapi import HTTPException
@app.get("/download/big/{filename}")
async def download_big_file(filename: str):def iter_file(path: str):with open(file=path, mode="rb") as tfile:yield tfile.read()# while chunk := tfile.read(1024*1024): # 1MB 缓冲区# yield chunkfile_path = "./测试任务.pdf"if not os.path.exists(file_path):raise HTTPException(status_code=404, detail="File not found")# # 支持浏览器预览# return StreamingResponse(content=iter_file(path=file_path), status_code = 200,)# 直接下载return StreamingResponse(iter_file(path=file_path), media_type="application/octet-stream", headers={"Content-Disposition": f"attachment; filename={filename}"})
然后使用浏览器下载:
http://127.0.0.1:8000/download/big/ceshi_big.pdf
1.3. 下载大文件(bytes)
import io
@app.get("/download/bytes/{filename}")
async def download_bytes_file(filename: str):def read_bytes(path: str):content = "Error"with open(file=path, mode="rb") as tfile:content = tfile.read()# # 失败,需要转成bytes输出# return contentreturn io.BytesIO(content)file_path = "./测试任务.pdf"if not os.path.exists(file_path):raise HTTPException(status_code=404, detail="File not found")# 解决中文名错误from urllib.parse import quote# return StreamingResponse(content=read_bytes(path=file_path), media_type="application/octet-stream", # headers={"Content-Disposition": "attachment; filename={}".format(quote(filename))})return StreamingResponse(content=read_bytes(path=file_path), media_type="application/octet-stream", headers={"Content-Disposition": "attachment; filename={}".format(quote(filename))})
1.4. 提供静态文件服务
FastAPI 允许开发者使用 StaticFiles 来提供静态文件服务。这类似于传统 Web 服务器处理文件的方式。
from fastapi.staticfiles import StaticFiles# app.mount("/static", StaticFiles(directory="static", html=True), name="free")
app.mount("/static", StaticFiles(directory="fonts", html=True), name="free")
尚未测试通过。
2. 客户端处理
参考(还有进度条, 带有断点续传的下载, 带有超时和重试的下载):
https://blog.csdn.net/u013762572/article/details/145158401
批量上传下载
https://blog.csdn.net/weixin_43413871/article/details/137027968
2.1. 普通下载
import requests
import os"""方式1,将整个文件下载在保存到本地"""
def download_file_bytes(file_name):# 以下三个地址均可以url = "http://127.0.0.1:8000/download/small/ceshi_samll.pdf"url = "http://127.0.0.1:8000/download/bytes/ceshi_bytes.pdf"url = "http://127.0.0.1:8000/download/big/ceshi_big.pdf"# response = requests.get(url, params={"filename": "1.txt"})response = requests.get(url)# print(response.text)with open(file_name, 'wb') as file:# file.write(response.text)file.write(response.content)if __name__ == '__main__':download_file_bytes("本地测试下载文件bytes.pdf")
2.2. 分块下载
import requests
import os"""方式2,通过流的方式一次写入8192字节"""
def download_file_big(file_name):# 以下三个地址均可以url = "http://127.0.0.1:8000/download/small/ceshi_samll.pdf"# url = "http://127.0.0.1:8000/download/big/ceshi_big.pdf"# url = "http://127.0.0.1:8000/download/bytes/ceshi_bytes.pdf"# response = requests.get(url, params={"filename": "./测试任务.pdf"}, stream=True)response = requests.get(url, stream=True)with open(file_name, 'wb') as file:for chunk in response.iter_content(chunk_size=8192):file.write(chunk)if __name__ == '__main__':download_file_big("本地测试下载文件big.pdf")
2.3. 显示进度条下载
import requests
import os
from tqdm import tqdmdef download_file_tqdm(file_name):# 以下三个地址均可以# url = "http://127.0.0.1:8000/download/small/ceshi_samll.pdf"# url = "http://127.0.0.1:8000/download/big/ceshi_big.pdf"url = "http://127.0.0.1:8000/download/bytes/ceshi_bytes.pdf"response = requests.get(url, stream=True)if response.status_code == 200:file_size = int(response.headers.get('content-length', 0))# 显示进度条progress = tqdm(response.iter_content(chunk_size=8192), total=file_size,unit='B', unit_scale=True)with open(file_name, 'wb') as f:for data in progress:f.write(data)return Truereturn Falseif __name__ == '__main__':download_file_tqdm("本地测试下载文件tqdm.pdf")
运行结果:
> python.exe .\fast_client.py
1.92kB [00:00, 14.0kB/s]
2.4. 带有断点续传的下载
# 带有断点续传的下载
def resume_download(file_name):# 以下三个地址均可以# url = "http://127.0.0.1:8000/download/small/ceshi_samll.pdf"# url = "http://127.0.0.1:8000/download/big/ceshi_big.pdf"url = "http://127.0.0.1:8000/download/bytes/ceshi_bytes.pdf"# 获取已下载文件大小initial_pos = os.path.getsize(file_name) if os.path.exists(file_name) else 0# 设置 Headerheaders = {'Range': f'bytes={initial_pos}-'}response = requests.get(url, stream=True, headers=headers)# 追加模式打开文件mode = 'ab' if initial_pos > 0 else 'wb'with open(file_name, mode) as f:for chunk in response.iter_content(chunk_size=8192):if chunk:f.write(chunk)
尚未测试
2.5. 带有超时和重试的下载
# 带有超时和重试的下载
from requests.adapters import HTTPAdapter
from requests.packages.urllib3.util.retry import Retry
import time
def download_with_retry(file_name, max_retries=3, timeout=30):# 以下三个地址均可以# url = "http://127.0.0.1:8000/download/small/ceshi_samll.pdf"# url = "http://127.0.0.1:8000/download/big/ceshi_big.pdf"url = "http://127.0.0.1:8000/download/bytes/ceshi_bytes.pdf"session = requests.Session()# 设置重试策略retries = Retry(total=max_retries,backoff_factor=1,status_forcelist=[500, 502, 503, 504])session.mount('http://', HTTPAdapter(max_retries=retries))session.mount('https://', HTTPAdapter(max_retries=retries))try:response = session.get(url, stream=True, timeout=timeout)with open(file_name, 'wb') as f:for chunk in response.iter_content(chunk_size=8192):if chunk:f.write(chunk)return Trueexcept Exception as e:print(f"Download failed: {str(e)}")return False尚未测试
2.6. 完整的下载器实现
import requests
from tqdm import tqdm
import os
from pathlib import Path
import hashlibclass FileDownloader:def __init__(self, chunk_size=8192):self.chunk_size = chunk_sizeself.session = requests.Session()def get_file_size(self, url):response = self.session.head(url)return int(response.headers.get('content-length', 0))def get_file_hash(self, file_path):sha256_hash = hashlib.sha256()with open(file_path, "rb") as f:for byte_block in iter(lambda: f.read(4096), b""):sha256_hash.update(byte_block)return sha256_hash.hexdigest()def download(self, url, save_path, verify_hash=None):save_path = Path(save_path)# 创建目录save_path.parent.mkdir(parents=True, exist_ok=True)# 获取文件大小file_size = self.get_file_size(url)# 设置进度条progress = tqdm(total=file_size,unit='B',unit_scale=True,desc=save_path.name)try:response = self.session.get(url, stream=True)with save_path.open('wb') as f:for chunk in response.iter_content(chunk_size=self.chunk_size):if chunk:f.write(chunk)progress.update(len(chunk))progress.close()# 验证文件完整性if verify_hash:downloaded_hash = self.get_file_hash(save_path)if downloaded_hash != verify_hash:raise ValueError("File hash verification failed")return Trueexcept Exception as e:progress.close()print(f"Download failed: {str(e)}")if save_path.exists():save_path.unlink()return Falsedef download_multiple(self, url_list, save_dir):results = []for url in url_list:filename = url.split('/')[-1]save_path = Path(save_dir) / filenamesuccess = self.download(url, save_path)results.append({'url': url,'success': success,'save_path': str(save_path)})return results# 使用示例
downloader = FileDownloader()# 单文件下载
url = "http://127.0.0.1:8000/download/bytes/ceshi_bytes.pdf"
downloader.download(url, save_path="downloads/file.pdf")# # 多文件下载
# urls = [
# "https://example.com/file1.pdf",
# "https://example.com/file2.pdf"
# ]
# results = downloader.download_multiple(urls, "downloads")
运行结果:
> python.exe .\fast_client_plus.py
file.pdf: 9.18MB [00:00, 60.2MB/s]
3. 异常处理
3.1. 中文文件名错误
下载文件时,当传递文件名为中文时,报错。
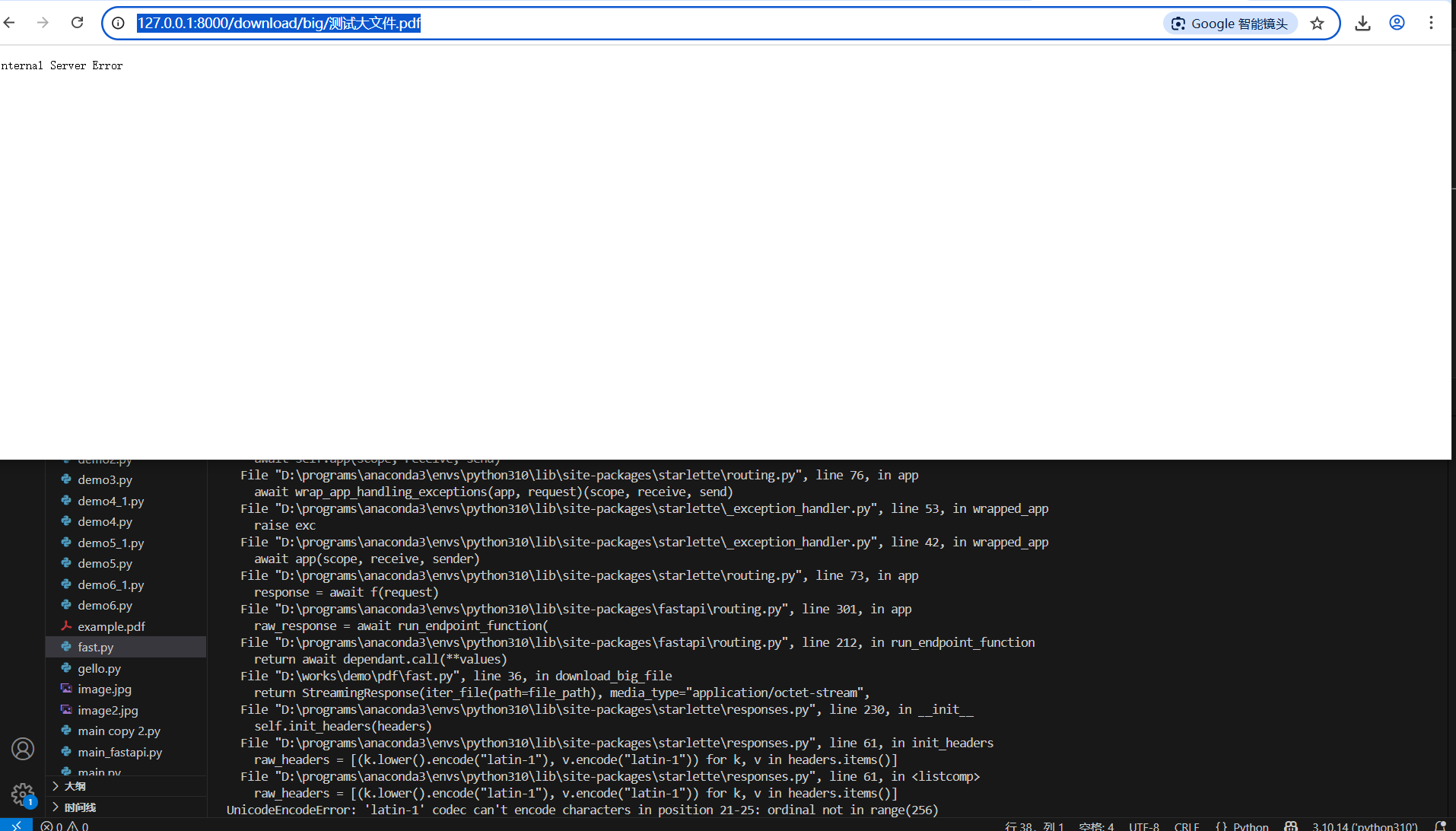
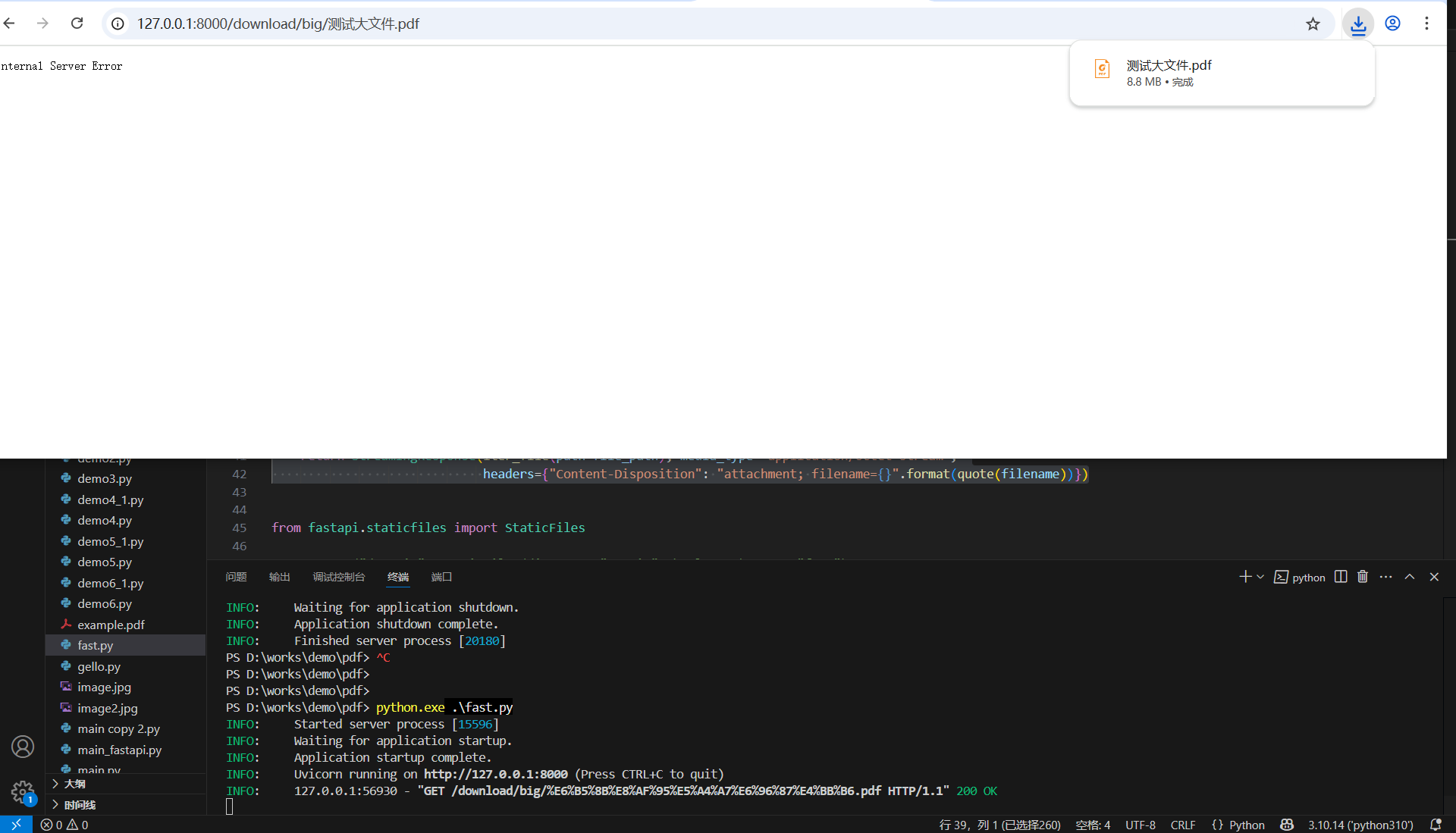
# 解决中文名错误from urllib.parse import quotereturn StreamingResponse(iter_file(path=file_path), media_type="application/octet-stream", headers={"Content-Disposition": "attachment; filename={}".format(quote(filename))})
3.2. 使用 mimetypes.guess_type
mimetypes.guess_type 是 Python 标准库 mimetypes 中的一个函数,用于根据文件名或 URL 猜测文件的 MIME 类型。该函数的基本用法如下:
import mimetypes
# 参数
# url:可以是文件名或 URL 的字符串。
# strict:一个布尔值,默认为True,表示仅使用 IANA 注册的官方 MIME 类型。如果设置为 False,则还包括一些常用的非标准 MIM E类型。
# 返回值
# 函数返回一个元组 (type, encoding):
# type:文件的 MIME 类型,如果无法猜测则返回 None。
# encoding:文件的编码格式,如果无法确定则返回 None。
mimetypes.guess_type(url, strict=True)
服务端修改 media_type
from urllib.parse import quotefrom mimetypes import guess_type# 返回一个元组 ('application/pdf', None)content_type = guess_type(file_path)[0]return StreamingResponse(content=read_bytes(path=file_path), media_type=content_type, headers={"Content-Disposition": "attachment; filename={}".format(quote(filename))})
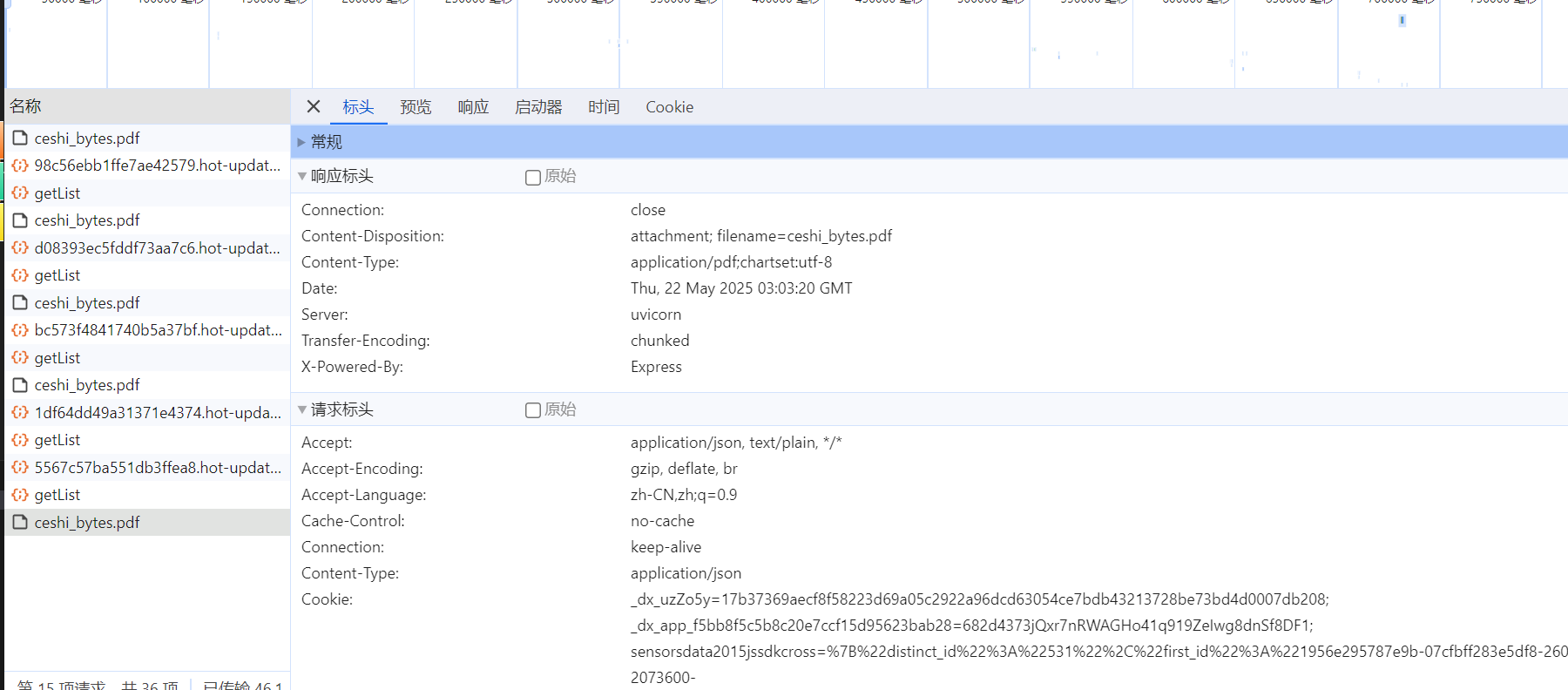
客户端返回:
{'date': 'Fri, 23 May 2025 01:04:55 GMT', 'server': 'uvicorn', 'content-disposition': 'attachment; filename=ceshi_bytes.pdf', 'content-type': 'application/pdf', 'Transfer-Encoding': 'chunked'}
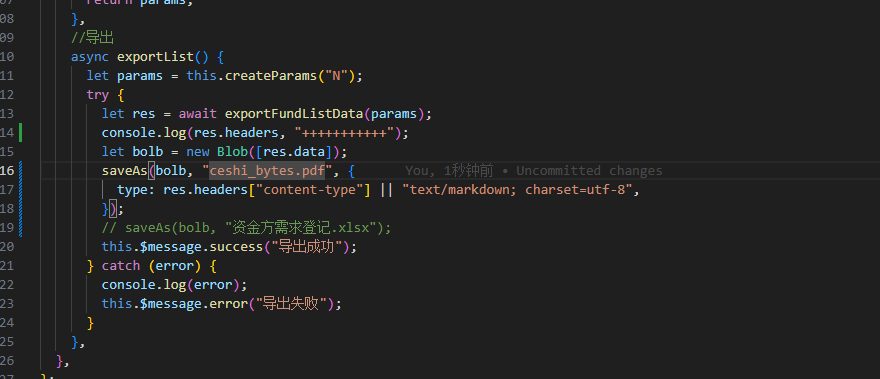
3.3. 使用 VUE Blob 下载乱码问题
前端大佬说:
content-type 应该是 application/pdf
response-type 应该是 blob