PCM音频数据的编解码
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、pandas是什么?
- 二、使用步骤
- 1.引入库
- 2.读入数据
- 总结
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
一、PCM是什么?
PCM(Pulse Code Modulation,脉冲编码调制)音频数据是未经压缩的音频采样数据裸流,它是由模拟信号经过采样、量化、编码及调制转换成的标准数字音频数据。
PCM是一种用数字表示采样模拟信号方法。主要包括采样,量化,编码三个主要过程。
描述PCM数据的主要参数:
◆ Sample Rate : 采样频率。8kHz(电话)、44.1kHz(CD)、48kHz(DVD)。
◆ Sample Size : 量化位数。常见值为8-bit、16-bit。
◆ Number of Channels : 通道个数。常见的音频有立体声(stereo)和单声道(mono)两种类型,立体声包含左声道和右声道。另外还有环绕立体声等其它不太常用的类型。
◆ Sign : 表示样本数据是否是有符号位,比如用一字节表示的样本数据,有符号的话表示范围为-128 ~ 127,无符号是0 ~ 255。
◆ Byte Ordering : 字节序。字节序是little-endian还是big-endian。通常均为little-endian。
◆ Integer Or Floating Point : 整形或浮点型。大多数格式的PCM样本数据使用整形表示,而在一些对精度要求高的应用方面,使用浮点类型表示PCM样本数据
需求:为了降低传输带宽,需要对音频数据进行压缩。
压缩首先想到的是把16bit的音频数据转为8bit。最简单的方式是均匀量化, >>8 (右移8位),但这样做会使得声音的噪音变大。最好的做法是使用非均匀量化(如A-Law),其原理是对于小音量的声音,其蕴含的信息量更大,人耳对小音量更敏感;而大音量部分则影响没那么大。因此使用非均匀量化的方式,对于小音量部分保留更多的数据,大音量部分则保留更少的数据。
二、算法原理
1.音频编解码国际标准
即可以用A-Law(A律)算法,也可以用uLaw(μ律),两种算法可相互转化。
令量化器过载电压为1,相当于把输入信号进行归一化,那么A律对数压缩定义为:
当0 <= x <
2.A律算法原理
即可以用A-Law(A律)算法,也可以用uLaw(μ律),两种算法可相互转化。
令量化器过载电压为1,相当于把输入信号进行归一化,那么A律对数压缩定义为:
当0 <= x <= 1/A时,f(x)=(Ax)/(1+lnA)
当1/A <= x <= 1时,f(x)=(1+lnAx)/(1+lnA)
现行的国际标准中A=87.6,此时信号很小时(即小信号时),从上式可以看到信号被放大了16倍,
这相当于A压缩率与无压缩特性比较,对于小信号的情况,量化间隔比均匀量化时减小了16倍,
因此,量化误差大大降低;而对于大信号的情况例如x=1,量化间隔比均匀量化时增大了5.47倍,
量化误差增大了。这样实际上就实现了“压大补小”的效果。
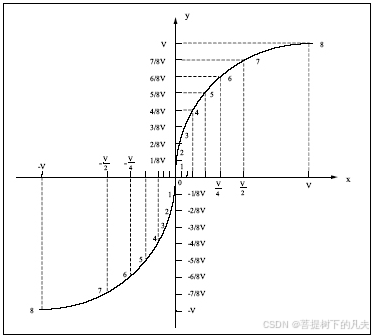
在程序中实现该曲线比较复杂。因此用8段折线来近似表示。
把x轴划分为不均匀的8份,第一点取1/2处,第二点取1/4处,第三点取1/8处……第七点取1/128.
把y轴划分为均匀的8分段。
2.读入数据
代码如下(示例):
data = pd.read_csv('https://labfile.oss.aliyuncs.com/courses/1283/adult.data.csv')
print(data.head())
该处使用的url网络请求的数据。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。