[爬虫实战] 爬微博图片:xpath的具体运用
博客配套代码发布于github:微博图片
相关知识点:图片懒加载 [爬虫知识] 数据解析
相关爬虫专栏:JS逆向爬虫实战 爬虫知识点合集 爬虫实战案例
这里我们以网页微博图片为例,尝试获取该页面下所有图片并保存。
一、分析网站
刷新网页后看到这个html文件:其中Content-type看到text/html且预览里面是整个页面布局,可以确定这是个html类型文件,侧重点在于如何xpath提取对应数据。
再看到文中有大量图片,且鼠标下滑时能在开发者工具中看到图片的不断缓存加载,证明这里用到了图片懒加载的知识(了解懒加载→图片懒加载)。
再把请求标头的各项参数看看,确定后就可以开写代码了。
二、爬取代码初始化
- 确认页面 -- url = 'https://blog.sina.com.cn/s/blog_01ebcb8a0102zj25.html'
- 确认请求头 -- headers = {
-
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36',
'referer':'https://blog.sina.com.cn/s/articlelist_32230282_1_1.html' - }
- 发起请求 -- response = requests.get(url,headers=headers).textq
请求响应成功:
得到该页面整体数据后我们就能开始进行数据解析了。
三、数据清洗
这时候我们再去找第一张图片的xpath试试看能不能获取
tree =etree.HTML(response.text)
title = tree.xpath('//*[@id="sina_keyword_ad_area2"]/a[1]/img/@title')[0]
print(title)
没问题,再具体分析一下各个图片的xpath关系:

大概能确定这里div为大标签,从div下面取到每个a标签的img标签,同时再取到真正的图片属性链接real_src就能得到我们想要的数据。测试一下:
if not os.path.exists('西安图片集'):os.mkdir('西安图片集')
img_link = tree.xpath('//*[@id="sina_keyword_ad_area2"]/a/img')
n = 1
for img in img_link:real_src= img.xpath('./@real_src')[0]response_detail = session.get(url=real_src,headers=header).contentwith open(f'./西安图片集/{n}.图片.png','wb') as f:f.write(response_detail)print(f'图片{n}写入完成!')breakn += 1难点分析:img_link = tree.xpath('//*[@id="sina_keyword_ad_area2"]/a/img')
原先直接选中那个img标签的xpath给的是 xx.xpath('//*[@id="sina_keyword_ad_area2"]/a[1]/img')这里a的[1]需要去掉,代表我们选择是这个@id下所有相关的a下面的img标签。此时的img_link返回的就是个列表项,接着可以用for循环得到其中每个项
另:图片写入时记得是二进制,返回数据要用content,写入要用wb模式,与常规的写入不太一样。
把break去掉再运行一下:
 ?为什么就十张,明明那页面里非常多的图片啊。
?为什么就十张,明明那页面里非常多的图片啊。
我们回到原页面再观察一下各标签:
 好家伙,竟然下面还藏着这么多div标签,所以我们应该写两套for循环,第一套img_link,第二套div_link,分别代表两套不同的xpath提取方式。(吐槽下这个前端页面写的真是...)
好家伙,竟然下面还藏着这么多div标签,所以我们应该写两套for循环,第一套img_link,第二套div_link,分别代表两套不同的xpath提取方式。(吐槽下这个前端页面写的真是...)
div_total_link = tree.xpath('//*[@id="sina_keyword_ad_area2"]')[0] # element对象必须以非列表形式才能xpath!!!
print(div_total_link)
img_link = div_total_link.xpath('./a/img')
div_link = div_total_link.xpath('./div/a/img')
n = 1
for img in img_link:real_src = img.xpath('./@real_src')[0]response_detail = session.get(url=real_src,headers=header).contentwith open(f'./西安图片集/{n}.图片.png','wb') as f:f.write(response_detail)print(f'图片{n}写入完成!')n += 1for div1 in div_link:real_src = div1.xpath('./@real_src')[0]response_detail = session.get(url=real_src,headers=header).contentwith open(f'./西安图片集/{n}.图片.png','wb') as f:f.write(response_detail)print(f'图片{n}写入完成!')n += 1print(f'全部爬取完成!总计爬取{len(img_link)+len(div_link)}张图片!')如上,写了第二个for循环后再把当初的那个大div标记成div_total_link,各自去它底下xpath,并完善相应逻辑。
最终得答: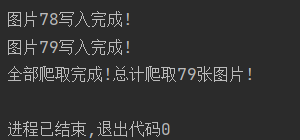 保存成功!
保存成功!
四、总结
在这种类似的反爬较少的网站,耐心的观察网页的各项属性标签,慢慢分析同时熟练使用xpath即可。