论文阅读笔记——Emerging Properties in Unified Multimodal Pretraining
BAGEL 论文
商业闭源系统与学术/开源模型的差距很大,BAGEL 旨在通过开源统一架构+大规模交错数据主要解决:
- 架构割裂:理解/生成分属两条网络,信息被压缩在少量条件 token 中,长上下文推理受限。
- 数据贫乏:主要依赖静态图文对,缺乏真实世界的时序、物理与因果信号。
- 能力天花板:在复杂任务(自由图像操控、未来帧预测、世界导航)上与闭源模型存在数量级差距。
随着交织多模态预训练规模扩大,基础多模态理解与高保真生成能力最先收敛;随后涌现复杂编辑与自由视觉操控能力;最终长上下文推理开始赋能多模态理解与生成,表明原本独立的原子技能协同形成了跨模态的组合推理能力。
当前主流架构有三种:
- 自回归视觉生成:使用离散视觉 tokenizer(如 VQGAN)将图像编码为 tokens,通过自回归 Transformer 直接预测下一 token(文本 / 视觉统一建模)。代表模型如 Janus、Chameleon 等。优势是架构简单,可复用现有 LLM 基建,易于实现端到端训练。但生成质量受限,视觉生成效果显著低于扩散模型(如 SDXL),因自回归的顺序生成难以建模复杂像素依赖;并且推理效率低,逐 token 生成导致长序列推理延迟高(如生成 1024x1024 图像需数千步)。
- 外接生成模型:使用 LLM 甚至 VLM 作为 backbone,生成语义 condition,通过轻量级 Adapter 连接预训练扩散模型,其基于语义 condition 生成图像。代表模型如 DreamLLM、SEED-X、MetaQuery、BLIP3-o等。优势是可复用预训练权重,收敛迅速;且受益于扩散模型的高保真图像合成能力,生成质量高。但存在语义瓶颈,LLM 需将长上下文压缩为少量 latent tokens(如 64x64 特征图),导致细节丢失,尤其在长序列推理中表现不佳;且跨模态交互弱,理解与生成模块通过Adapter间接连接,难以实现深度语义对齐。
- 统一集成 Transformer:将 LLM 与扩散模型统一在单个 Transformer 架构中,共享自注意力层,支持端到端跨模态推理。代表模型如Transfusion、JanusFlow等。优势是无交互瓶颈,文本、图像、视频 tokens 在同一 Transformer 层中直接交互,避免信息压缩;且可扩展性强,支持大规模交错数据训练,兼容长上下文和复杂任务;最重要的是通过共享参数,理解与生成能力可协同优化,促进复杂推理能力的涌现。但存在的挑战很明显,训练成本高,需同时优化语言建模与扩散生成,计算资源需求显著高于前两类方案。
字节这篇工作核心是通过交错多模态数据(包括图像、视频、导航等多种信息),结合更多场景的导航数据,把多模态信息直接作为模型输入,而不是像以前那样把视觉等信息仅作为文字条件或辅助提示。模型内部通过分离的FFN和KV机制设计,保证不同模态数据既能保持各自特征,又能互相影响和融合,增强了跨模态的深度理解和推理能力。底层模型基于Qwen2.5做调整和优化,使得这套架构能很好支持论文里提到的图像理解、视频处理、导航等复杂任务,实现更强的多模态交互和应用。
这样,模型不再是单向地用文字去“控制”图像信息,而是多模态数据间双向、甚至多向地相互作用。

在训练过程中,构建了三种视觉表征:噪声化 VAE 表征(用于 Rectified-Flow)、纯净 VAE 表征(作为图像/文本 token 生成的条件输入)、ViT 视觉表征(统一不同模态数据输入规范)——区分扩散与自回归生成。使用了广义因果注意力,采用 Pytorch FlexAttention,KV 缓存规则——仅存储纯净的 VAE 表征和 ViT 视觉表征(噪声 VAE 是前向扩散阶段的噪声预测,仅用于 MSE);图像生成完成后,上下文的含噪 VAE 标记被替换为纯净版。采用 Classifier-Free Guidance,对文本采用 10% 的 dropout,ViT 采用 50% 的 dropout,纯净 VAE 采用 10% 的 dropout。
理解专家(处理Text / ViT tokens)与生成专家(处理 VAE tokens)共享自注意力层,实现语义信息的无损传递(如下图所示,MoT 架构的 MSE 损失收敛更快,CE Loss也稳定更低)。

覆盖文本、图像、视频、网页四大模态,总量达数万亿token。
- 视频-文本交错数据:来自公开视频库(如 YouTube 教育视频、科普短片)+ 开源数据集 Koala36M(含交互场景)、MVImgNet2.0(多视角物体数据)。
- 网页-文本交错数据:来自OmniCorpus 网页数据集(含教程、百科、设计文档)+ 结构化编辑数据集(如 OmniEdit、UltraEdit)。
- 以及推理以增强数据:包括文生图、自由图像操控和智能编辑,使用开源VLM/LLM辅助构建推理过程。
训练时采用四阶段渐进训练:
- 对齐阶段:仅训练视觉 - 语言连接器,对齐 ViT 与语言模型。
- 预训练阶段:全模型训练,以图像 - 文本对为主(占比 60%),初步掌握基础生成。
- 持续训练阶段:提升视频 / 网页数据比例(各占 15%),增加分辨率至 1024x1024,强化长上下文推理。
- 监督微调阶段:精选高质量指令数据,优化多轮对话与复杂编辑。
实验
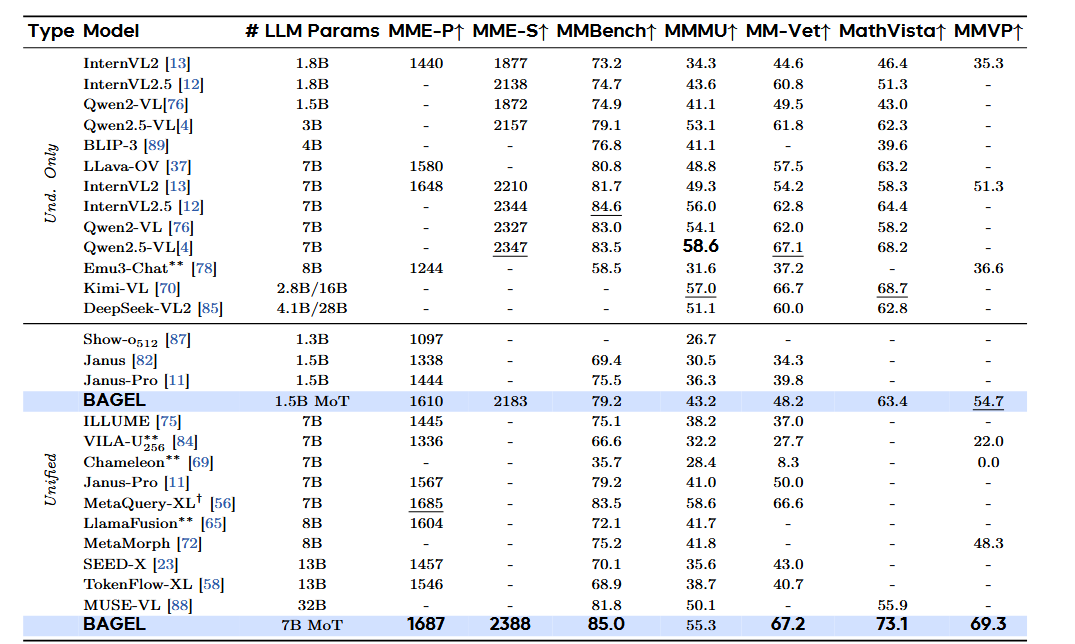
在 MMMU 和 MM-Vet 基准测试中,BAGEL显著超越开源统一模型Janus-Pro,提升了 14.3 分和 17.1 分。与 Qwen2.5-VL 和 InternVL2.5 等专用理解模型相比,BAGEL 在大多数这些基准测试中表现出更优越的性能,这表明我们的 MoT 设计在保持强大视觉理解能力的同时,有效缓解了任务冲突。
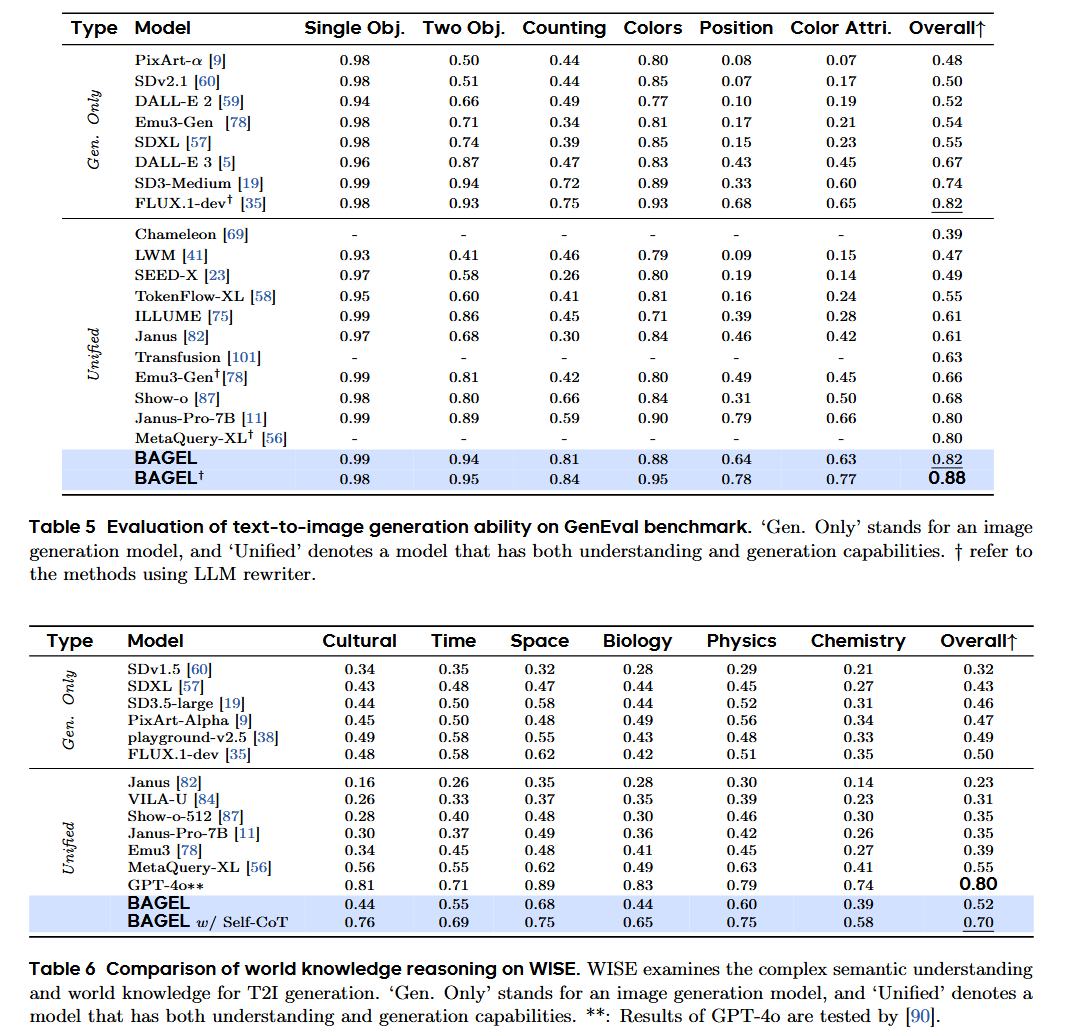
采用GenEval评测物体对齐与属性生成能力,采用WISE评测世界知识推理能力,从上表定量结果可以发现:在GenEval上BAGEL取得88% 总分,超越 SD3-Medium(74%)、Janus-Pro(80%),接近 FLUX.1-dev(82%)。在WISE上,BAGEL取得52% 原始得分,启用 “CoT” 后提升至 70%,比未使用 CoT 的版本高出 0.18,且显著超越了所有现有开源模型(之前的最佳成绩为 MetaQuery-XL 的 0.55),逼近 GPT-4o(80%)。
