3. OpenManus-RL中使用AgentGym建立强化学习环境
AgentGym概述
AgentGym是为评估和开发大模型agent而设计的支持多环境和多任务的框架。该框架统一采用ReAct格式,提供多样化的交互环境和任务,支持实时反馈和并发操作。
What is Ai Agent(基于大模型的智能体)?
首先是人造实体,且具备以下3种能力
能力1 环境感知; 能力2 决策或推理
能力3 行动,如调用工具或,语言输出,其他模态输出
训练基于LLM的agent两种方式
1 行为克隆方法
让专家(人或专家模型)来标注数据,agent去模仿这些标注好的数据
- 优势:稳定,可以混合各类数据来训练解决通用问题的agent
- 缺点:1 标注数据昂贵很难scaling 2 agent不会跟环境交互,缺乏探索学习过程(这类过程对于agent自我提升或训练时非常重要的)
2 交互式训练范式
agent跟环境充分交互,根据环境反馈来优化自身。如 犯错->跌打->爬起来->积累经验 再犯错再累积经验 - 优点:减少了对专家数据的依赖,并且能充分探索环境
- 缺点:目前这类的交互式训练主要针对的是单环境特定领域的agent
交互式训练研究现状
开发能够在人类水平上跨不同环境执行各种任务的agent一直是AI社区的长期目标。大型语言模型由于其泛化能力被认为是构造基于llm通用agent的一个很有前途的基础。但现在构建基于大语言模型通用agent智能体仍存在挑战,基于大模型的Agent在做强化学习时需要构建环境env以及定义任务task,但之前交互式训练范式工作主要是在单一的环境里面,而我们目前需要构建能处理多环境多任务的较为通用agent。
AgentGym工作目标
构建能在多样化的环境中进行自我进化并且具有某种通用多任务能力的agent
实现目标的三大挑战
1 交互式训练平台 (框架)
- 需包含多样化的环境 任务,能让agent去交互去进行全面地优化(最重要)
- 需支持并发,并行地与智能体agent交互
2 适当大小的轨迹的数据集(数据)
需要适当大小的轨迹的数据集。也就是初始数据集来训练一个具备初步智能体能力,或具备初步序列决策能力和前序知识的基础智能体。
这有助于智能体在更大的环境中去进一步探索和优化。因为在多样化很复杂的环境中让智能体从零开始不断尝试和犯错来学习所有知识的效率非常低,通常需要一个warm up 。
3 有效且灵活的进化方法 (算法)
让智能体在多个环境中进化,涉及到agent如何与环境互动,如何利用环境反馈信息实现自我进化。
探索AgentGym
AgentGym主要贡献
AgentGym主要贡献,提出了一个新的框架AGENTGYM。AGENTGYM包括一个多agent环境的交互平台,一个基准测试集AGENTTEVAL,以及两个轨迹集AGENTTRAJ和AGENTTRAJ-L,一种新的基于LLM的agent进化算法AGENTEVOL。
AgentGym交互式训练平台(解决第一个挑战)
AgentGym包括14个智能体环境,89个不同任务(如web任务,文本游戏任务,具身任务)。通过统一的接口,实现agent与环境间的多轮交互和实时反馈,同时也标准化来 任务规范,环境设置和agent的观察/动作空间。AgentGym框架概述图如下所示:
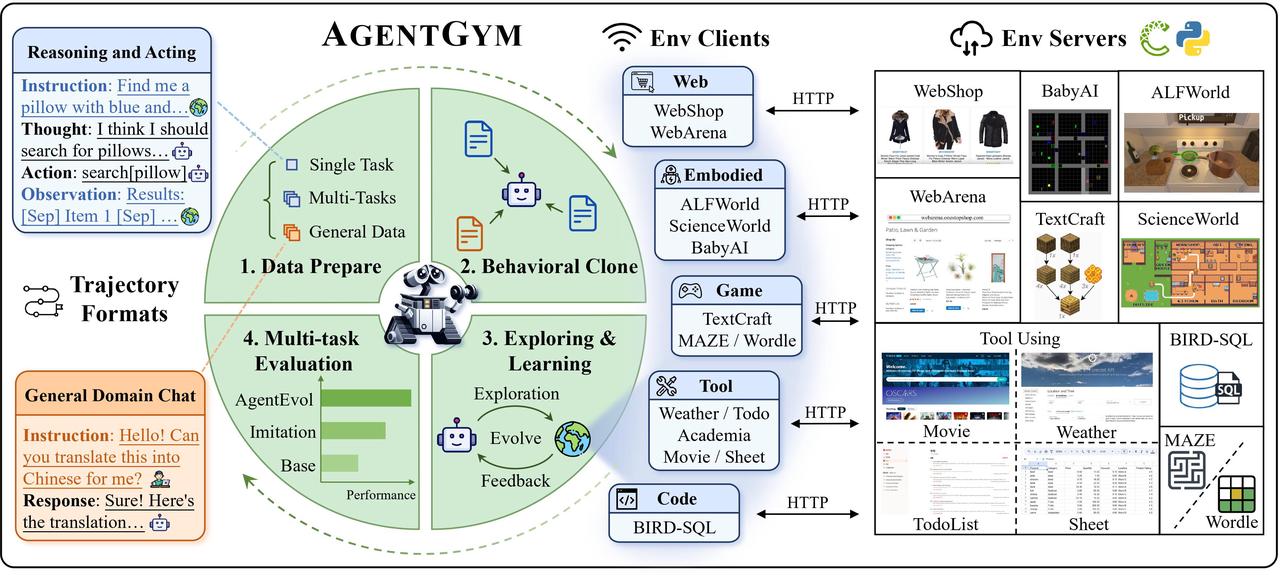
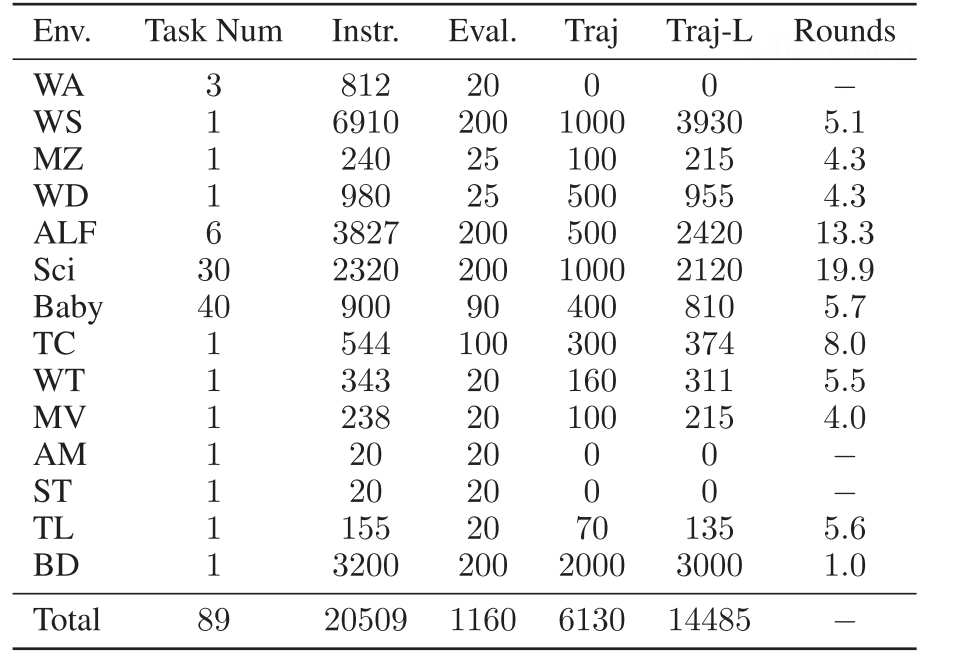
AgentGym的各个环境的任务数,指令集大小,测试集大小,轨迹集大小(traj,traj-L),每个环节平均轮次
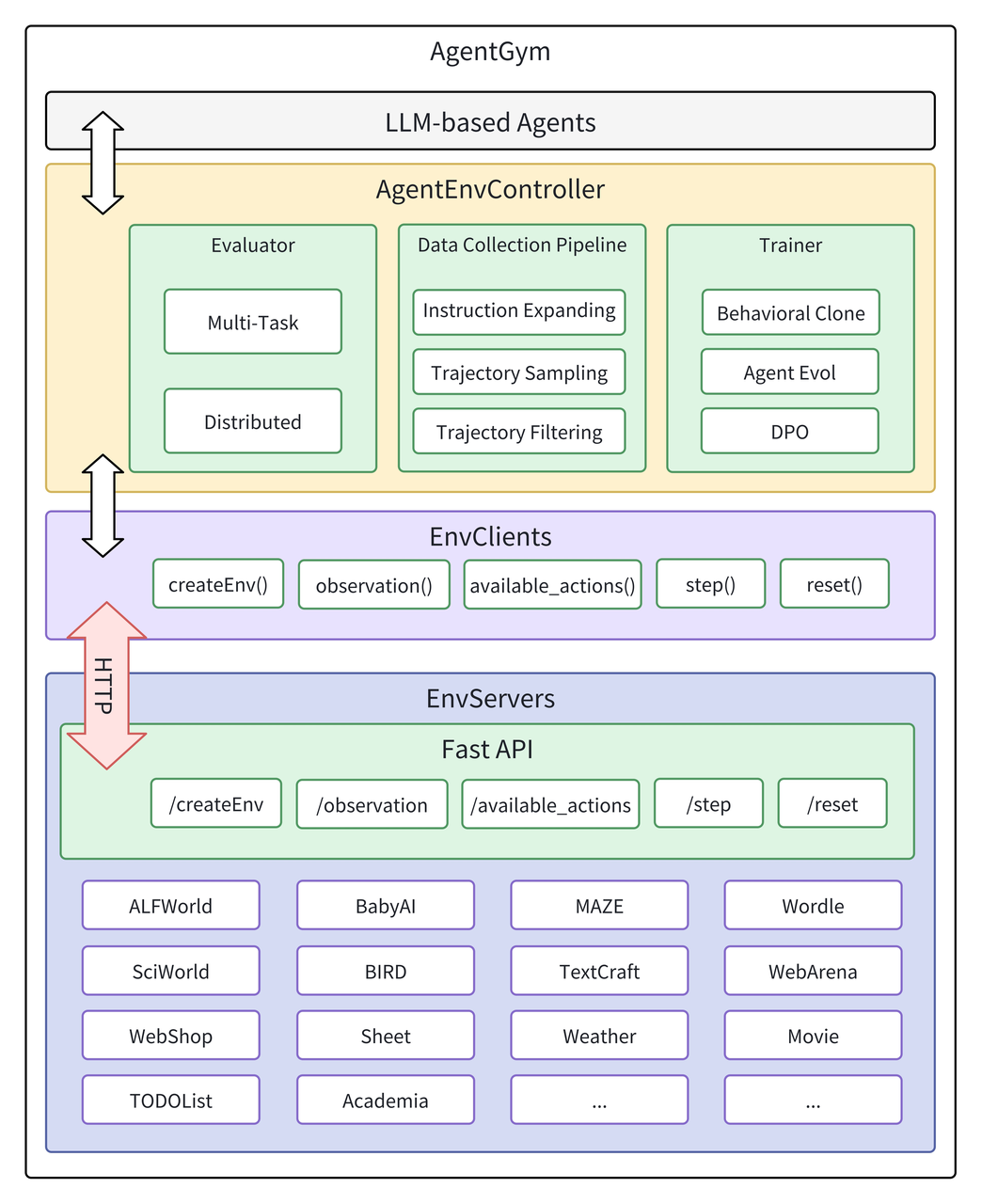
AgentGym平台架构主要由下面四个模块组成:
LLM-based Agents <—> AgentEnvController <—> EnvClients <—> EnvServers
- LLM-based Agents: 两个属性 大模型和分词器tokenizer。
- AgentController: 是我们连接agent和环境的核心组件。它负责评估agent、数据收集和训练agent。
- EnvClients:负责接收服务器提供的服务,并将其封装为用户调用的功能。
- EnvServers: 部署在不同的服务器或端口上,并通过的HTTP(用Fastapi来实现)提供服务。这使环境(EnvServers)与其他部分脱钩。提供了创建、销毁、观察、获取可用动作、执行动作、重置环境等 API 接口
AgentGym平台架构图如下所示:
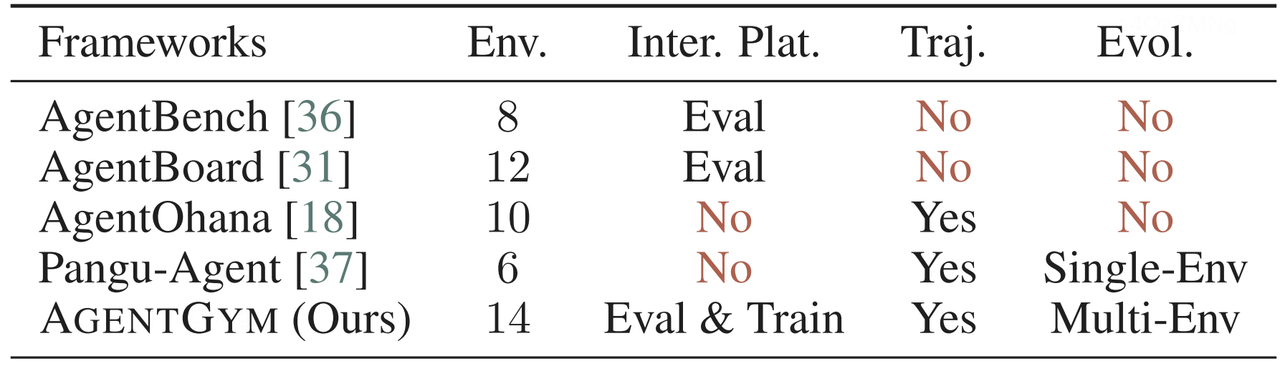
AgentGym提供交互式训练和评测平台。包含更多环境, 支持并发地,可持续的交互来帮助数据收集与智能体进化。下表是agentgym与其他agent框架的对比。
数据集构建(解决第二个挑战)
文中指出需要构建以下三类数据集
Expanded instructions
benchmark suite
high-quality interactive trajectories across environments
可扩展的指令数据集
基准测试套件
跨环境的高质量交互轨迹
指令数据集 :通过众包 和 基于AI(self-instruct [33] and instruction evolution,例如 prompting GPT-4 来生成instruction)的方式,从各种环境和任务中收集instructions(20509个)。指令包括任务描述,环境设置,给agent提问等指令。
基准测试套件:从收集的instructions中选个子集(1160个)当作测试集 benchmark suite 称为AgentEval,用来评估agent。
跨环境的高质量交互轨迹:使用众包(crowdsource)标注轨迹集和sota模型(GPT-4-Turbo)形成轨迹集,严格过滤根据奖励或正确性确保数据质量,最后形成6130条轨迹,称为为AgentTraj,用来训练 base agent(行为克隆)。为了公平比较,使用相同的pipeline对所有的指令标注和过滤,还收集了更大的轨迹集AgentTraj-L(论文讲座中讲的是所有轨迹)作为一个baseline, 代表行为克隆方法性能上限。
⚠️上述收集的数据在论文附件 C 中。
进化算法AgentEvol(解决第三个挑战)
AgentEvol重点是研究agent在面对以前看不见的任务和指令(训练集中没有的任务和指令)时是否能进化自己,这需要他们进行探索并从新的经验中学习。
POMDP和ReAct
Pomdp为部分可预测马尔可夫决策过程是强化学习领域处理不完全信息环境的核心数学模型。MDP假设环境状态完全可观测,而POMDP允许agent通过部分观测(如传感器数据、文本反馈)推断真实状态。具体agent通过贝叶斯更新维护对当前状态的概率分布,使agent能在不确定环境中持续修正对环境的认知。
ReAct即模型回答前先输出推理的过程。二者在强化学习中结合起来表示如下图所示:
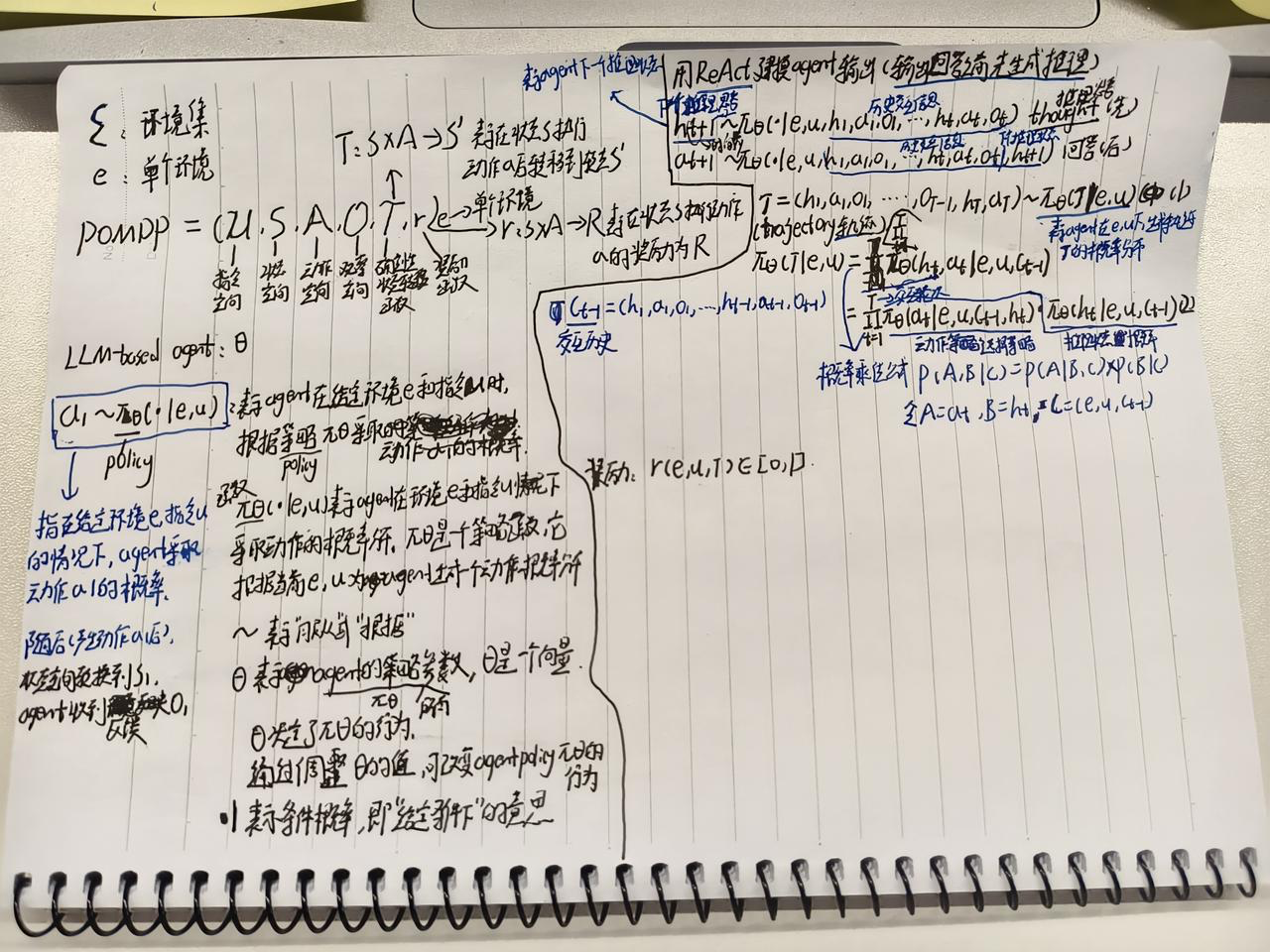
行为克隆训练base agent
通过行为克隆(behavioral cloning)方法用AgenTraj轨迹集 (Ds) 来训练一个基本的通用agent,使其具备基本的交互能力。在该agent基础上来使用进化算法。agent的 thought为h, action为a, baseagent用 πθbase表示。
行为克隆目标函数公式如下:
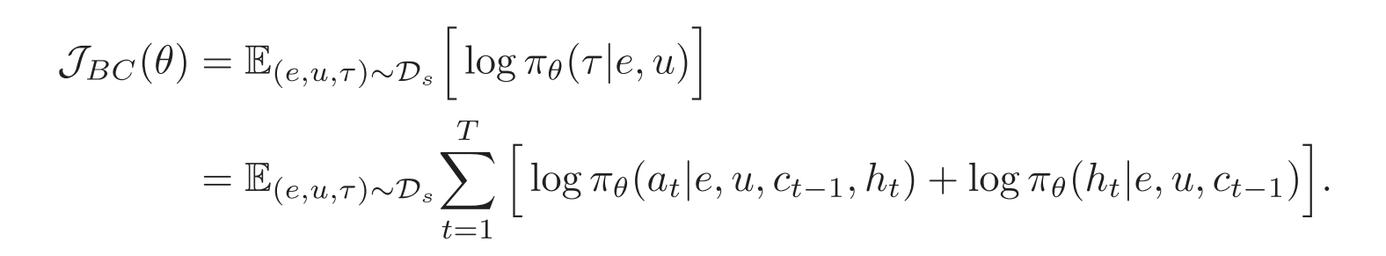
核心逻辑:让智能体(参数为 θ)模仿专家策略,使得在给定环境 e 和指令 u 时,智能体生成轨迹 τ 的概率 πθ(τ∣e,u) 尽可能接近专家轨迹。也就是求目标函数最大化。
公式第二步-时间步分解:将专家轨迹概率拆解为每个时间步 t 的思考和动作步骤的联合概率。 因为专家轨迹的概率是多个时间步联合概率的连乘,因为乘积会导致计算复杂、数值不稳定。取 log 将对数应用于乘积,转化为求和。
标准RL公式
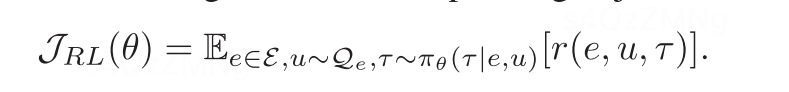
但是由于大采样空间和agent任务的长期特性,需引入概率推理改进标准RL。
Learning from estimated optimal policy
从预估的最优策略中学习,将 RL 视为特定概率模型中推理问题,用P(O = 1) 表示“通过最大期望奖励 获得最优策略”或“在rl任务中取得成功”的事件,这可以通过在每个采样点 对最优策略概率进行积分来计算。the policy agent 为πθ, 最优策略可以通过最大化下面公式结果来获得。
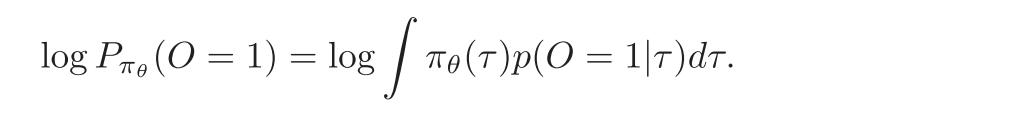
但是,基于llm的agent需要 token-wise 反馈来更新梯度,所以上述公式难以直接进行。故引入最优策略的估计函数q来构造 Eq5的变分下届,利用Jensen不等式得到如下公式:
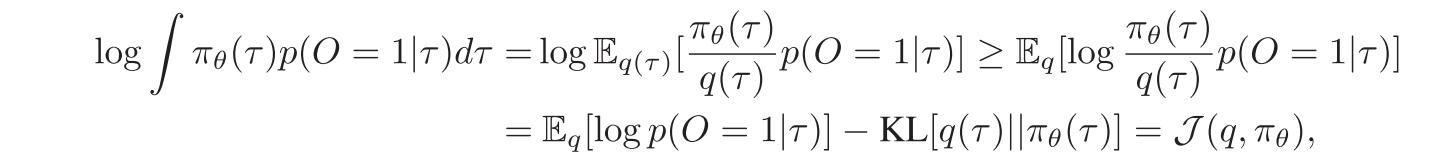
最后结果的前一项表示agent在状态空间上最大化期望奖励来估计采样轨迹上的最优策略分布。后一项表示将agent当前参数θ更新为最优策略q,完成一次优化迭代。其中πθ是agent诱导的轨迹分布,q(τ)是变分分布。
下面是对该公式参数以及公式的解释:
q(τ):
- 作用:作为agent的 变分分布,用于近似难以直接优化的真实轨迹分布(如专家策略或高回报轨迹的分布)。
- 设计目的:
- 替代原始策略 πθ(τ),简化期望计算;
- 通过重要性采样(Importance Sampling)将复杂积分转换为可优化的期望形式。
Eq(τ):
- 数学意义:表示对所有可能轨迹 τ 的期望值计算,但轨迹的权重由变分分布 q(τ) 的概率密度决定。
- 公式形式:
E q ( τ ) [ f ( τ ) ] = ∫ f ( τ ) ⋅ q ( τ ) d τ Eq(τ)[f(τ)]=∫f(τ)⋅q(τ)dτ Eq(τ)[f(τ)]=∫f(τ)⋅q(τ)dτ 即对函数 f(τ) 在所有轨迹上按 q(τ) 的概率加权求和(或积分)。

AGENTEVOL algorithm (本篇论文中强化学习)
由于对数函数的单调性,通过最大化下界J(q,πθ),我们可以得到一个期望收益比以前更高的策略。

- 探索步(Exploration Step):
通过最大化期望奖励,更新对最优策略的估计 qm+1,使其更倾向于高奖励轨迹。 - 学习步(Learning Step):
通过最小化KL散度,更新策略参数 θ,使当前策略 πθ 逼近探索步得到的最优估计 qm+1。
励等。
Openmanus-RL中如何添加新环境
OpenManus-RL 是一个用于训练大型语言模型(LLM)执行智能体任务的强化学习框架。结合了两个主要仓库:
- AgentGym:提供环境、奖励和智能体任务的评估工具
- Verl:处理强化学习训练、轨迹生成方法和奖励计算
AgentGym框架组件
该项目总体架构包括以下几个主要组件:
AgentGym/
├── agentenv/ # 核心包,包含主要功能实现
│ ├── agentenv/ # 框架主要模块
│ │ ├── controller/ # 控制器模块,用于连接智能体与环境
│ │ ├── envs/ # 环境客户端实现,每个文件对应一种环境
│ │ └── trainer/ # 训练器,包含行为克隆和智能体演化的实现
│ ├── examples/ # 使用示例
│ └── utils/ # 工具函数
├── agentenv-webshop/ # WebShop环境服务器实现
├── agentenv-webarena/ # WebArena环境服务器实现
├── agentenv-tool/ # 工具使用相关环境服务器实现
├── agentenv-textcraft/ # TextCraft环境服务器实现
├── agentenv-sciworld/ # SciWorld环境服务器实现
├── agentenv-sqlgym/ # SQL相关环境服务器实现
├── agentenv-lmrlgym/ # LMRL环境服务器实现
├── agentenv-alfworld/ # ALFWorld环境服务器实现
├── agentenv-babyai/ # BabyAI环境服务器实现
├── docs/ # 文档
└── assets/ # 资源文件,如图片等
控制器模块 (controller/)
控制器模块是整个AgentGym框架的核心组件,充当智能体与环境之间的桥梁,负责协调它们之间的交互,管理数据流动,并提供评估和训练的基础设施。该模块由以下几个关键文件组成:
- agent.py: 定义了智能体的基本接口
- env.py: 提供环境客户端的抽象接口
- task.py: 实现任务的基本框架和会话处理
- utils.py: 包含控制器BaseAgentEnvController、评估器Evaluator(BaseAgentEnvController)和训练器BaseTrainer(BaseAgentEnvController)的实现
- init.py: 导出模块的主要组件
环境模块 (envs/)
每个环境都有一个对应的客户端类(如WebshopEnvClient)和任务类(如WebshopTask),分别继承自BaseEnvClient和BaseTask。环境包括:
- WebShop
- WebArena
- MAZE
- Wordle
- ALFWorld
- SciWorld
- BabyAI
- TextCraft
- Weather
- Movie
- Academia
- Sheet
- TODOList
- BIRD (SQL)
训练器模块 (trainer/)
- AgentEvolTrainer: 智能体演化训练器
- BCTrainer: 行为克隆训练器
数据流向
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 输入指令 │───────► │ 智能体 │───────► │ 环境客户端 │
└─────────────┘ └─────────────┘ └─────────────┘▲ │ ││ │ ││ ▼ ▼
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 反馈 │◄─────────┤ 控制器 │◄─────────┤ 环境服务器 │
└─────────────┘ └─────────────┘ └─────────────┘▲ ││ ││ ▼
┌─────────────┐ ┌─────────────┐
│ 评估结果 │◄─────────┤ 评估器 │
└─────────────┘ └─────────────┘
Openmanus-RL中添加新环境
- 准备环境包:
- 在 openmanus_rl/agentgym/agentenv-<env_name>/ 中创建专用目录
- 在openmanus_rl/agentgym/agentenv-<env_name>/目录下创建 environment.yml 用于 conda 环境规范,如下所示:
name: agentenv-new_env # 新环境名 new_env
channels:- conda-forge- defaults
dependencies:- python=3.8.13- faiss-cpu=1.7.4- openjdk=11.0.21
- 在openmanus_rl/agentgym/agentenv-<env_name>/目录下创建 setup.sh 用于任何额外的设置步骤,如下所示:
pip install -U "Werkzeug>=2,<3" "mkl>=2021,<2022"cd ./new_env
bash ./setup.sh -d small
pip install -U "typing_extensions<4.6.0" "gym==0.23.1"
python -m spacy download en_core_web_lg
cd ..pip install -U python-Levenshtein
pip install -r requirements.txtpip install -e .pip uninstall numpy -y
pip install numpy
-
更新训练脚本:
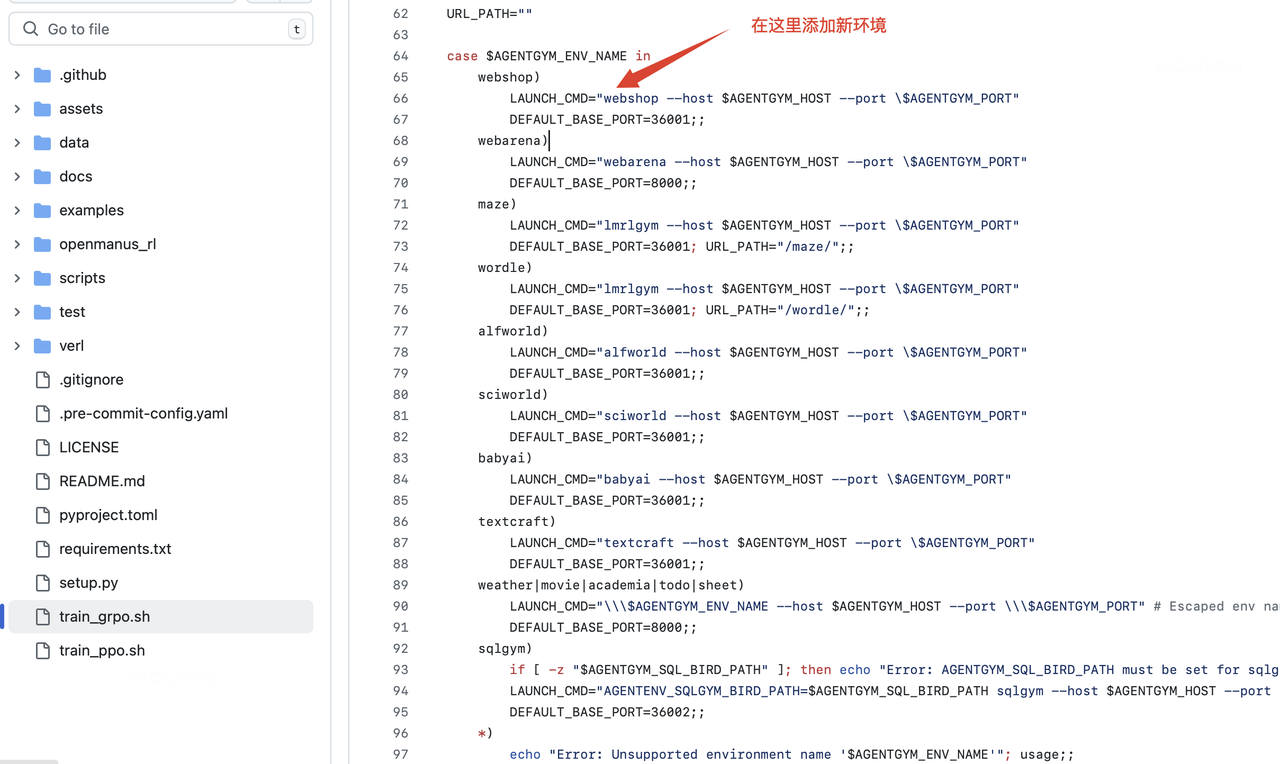
-
更新 OpenManus 智能体(openmanus_rl/llm_agent/openmanus.py):
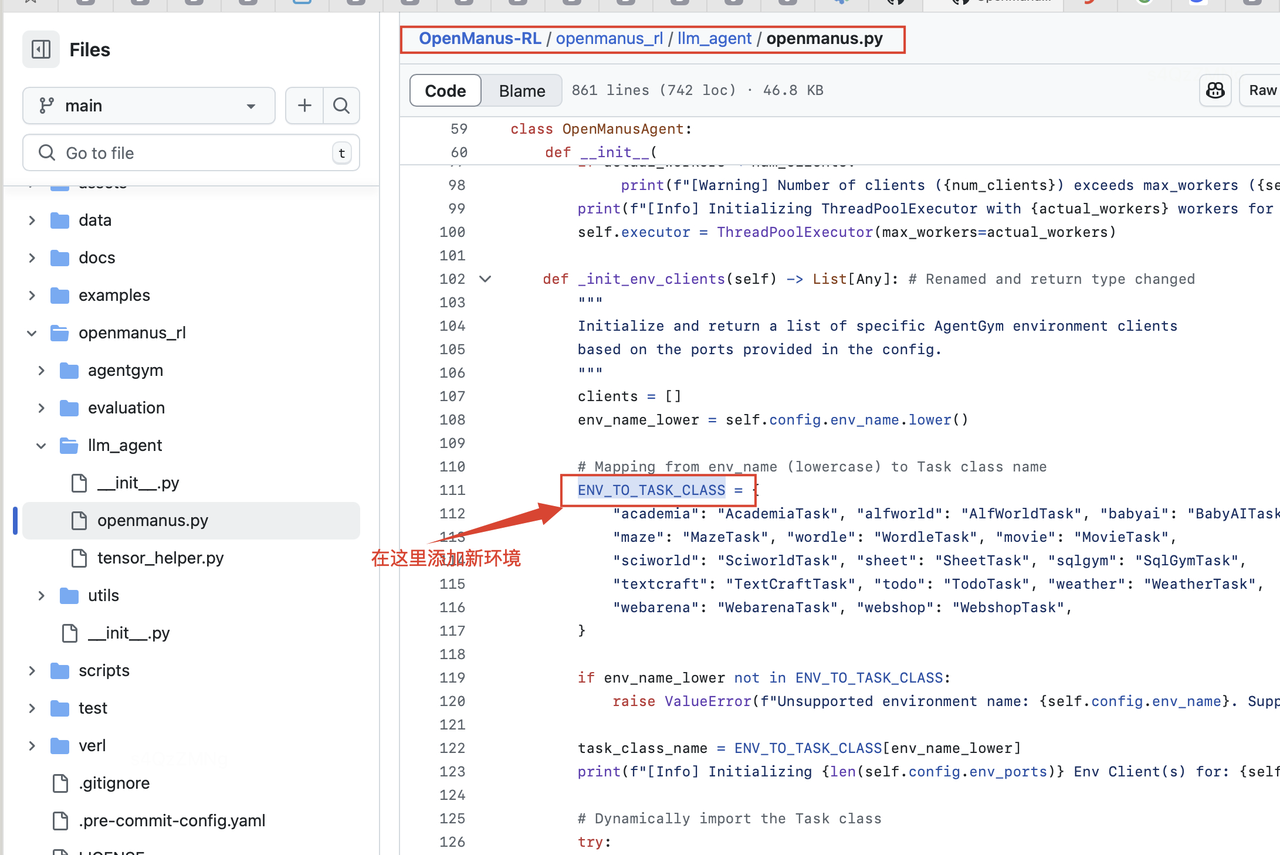
-
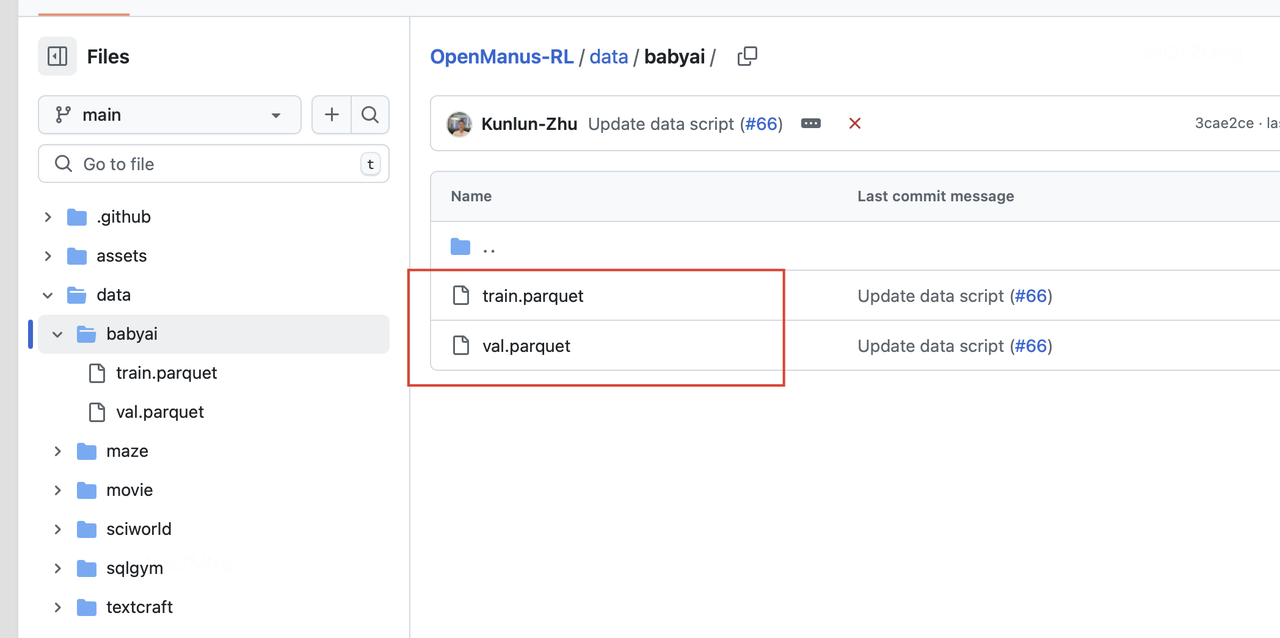
准备训练数据:
- 在 data/<env_name>/ 中创建用于训练/验证的 parquet 文件
- 在数据中定义适当的奖励模型
- 测试集成:
./train_ppo.sh --env_name new_env
AgentGym项目结构文档:https://github.com/OpenManus/OpenManus-RL/blob/main/openmanus_rl/agentgym/2nd_dev_docs/
相关探讨
后续工作
训练的整个流程为:将我们的环境封装起来,提供agent连接到rollout系统 收集轨迹,并根据优秀轨迹训练,更新模型。
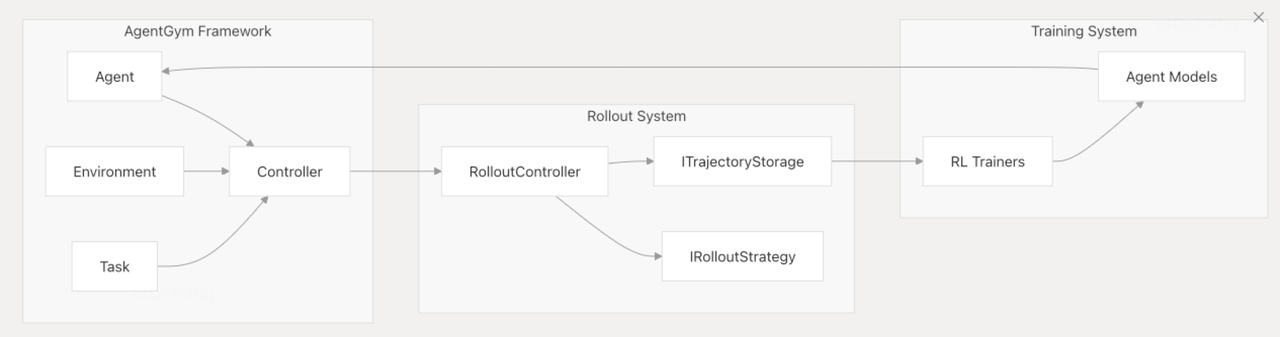
问题探讨
OpenManus-RL官方roadmap中指出Agent Environment Setup 来自于 Openmanus。
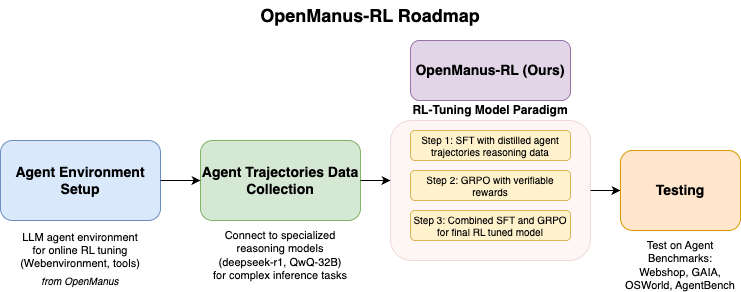
但我在OpenManus-RL官方飞书群咨询,如何把自己的OpenManus作为环境整合到OpenManus-RL中,有官方的人回答还在更新中。但通过上述学习和分享,若把自己的openmanus成功整合到OpenManus-RL中,我们就可以提供一个例子供他人参考,我们组也许能成为OpenManus-RL代码贡献者之一。
参考文档
论文摘要:https://agentgym.github.io
论文:https://arxiv.org/abs/2406.04151
论文讲座:https://www.bilibili.com/video/BV1RDHYeYE9C/?spm_id_from=333.337.search-card.all.click&vd_source=5afc56aaa0d4664e2b8f364e5e347a45
代码:https://github.com/WooooDyy/AgentGym.git
https://github.com/OpenManus/OpenManus-RL/tree/main/openmanus_rl
AgentGym项目结构文档:https://github.com/OpenManus/OpenManus-RL/blob/main/openmanus_rl/agentgym/2nd_dev_docs/
AgentGym二次开发设计文档:https://github.com/OpenManus/OpenManus-RL/blob/main/openmanus_rl/agentgym/2nd_dev_docs/
OpenManus-RL开发指南: https://github.com/OpenManus/OpenManus-RL/blob/main/docs/DEVELOPMENT_GUIDE_ZH.md
OpenManus-RL:https://deepwiki.com/OpenManus/OpenManus-RL
OpenManus模型训练概述:https://github.com/OpenManus/OpenManus-RL/blob/main/docs/README_ZH.md