阿里开源 CosyVoice2:打造 TTS 文本转语音实战应用
1、引言
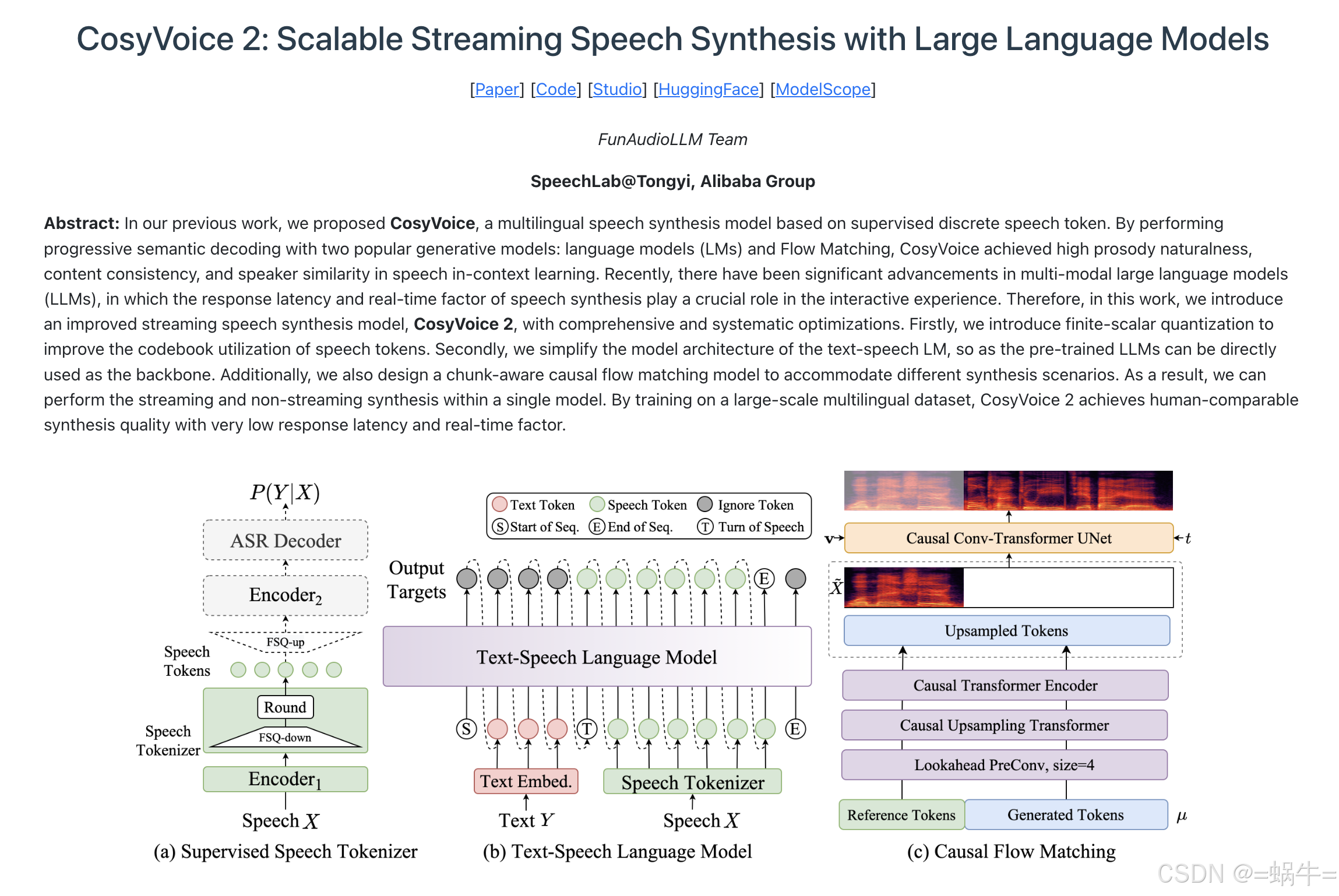
1.1、CosyVoice2 简介
阿里通义实验室推出音频基座大模型 FunAudioLLM,包含 SenseVoice 和 CosyVoice 两大模型。
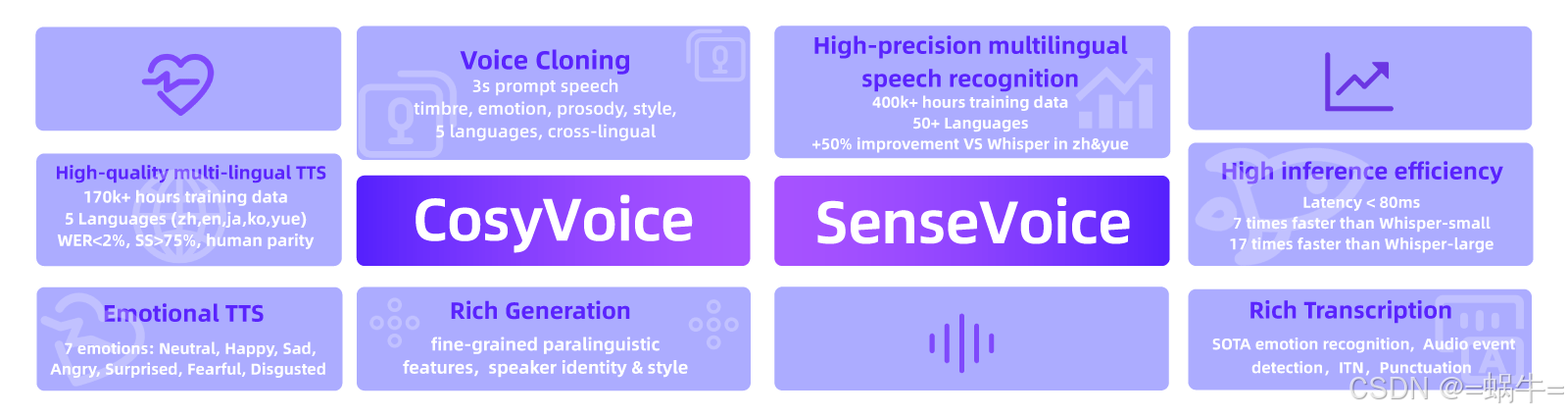
CosyVoice:模拟音色与提升情感表现力
多语言
- 支持的语言: 中文、英文、日文、韩文、中文方言(粤语、四川话、上海话、天津话、武汉话等)
- 跨语言及混合语言:支持零样本的跨语言和代码转换场景的语音克隆。
超低延迟
- 双向流支持: CosyVoice 2.0 集成了离线和流式建模技术。
- 快速首包合成: 在保持高质量音频输出的同时,实现了低至150毫秒的延迟。
高精度
- 改进发音: 与CosyVoice 1.0相比,减少了30%到50%的发音错误。
- 基准测试成就: 在Seed-TTS评估集的困难测试集中达到了最低字符错误率。
强稳定性
- 音色一致性: 确保了在零样本和跨语言语音合成中的可靠音色一致性。
- 跨语言合成: 相比1.0版本有了显著提升。
自然体验
- 增强韵律和音质: 改善了合成音频的一致性,将MOS评分从5.4提高到了5.53。
- 情感和方言灵活性: 现在支持更多细粒度的情感控制和口音调整。
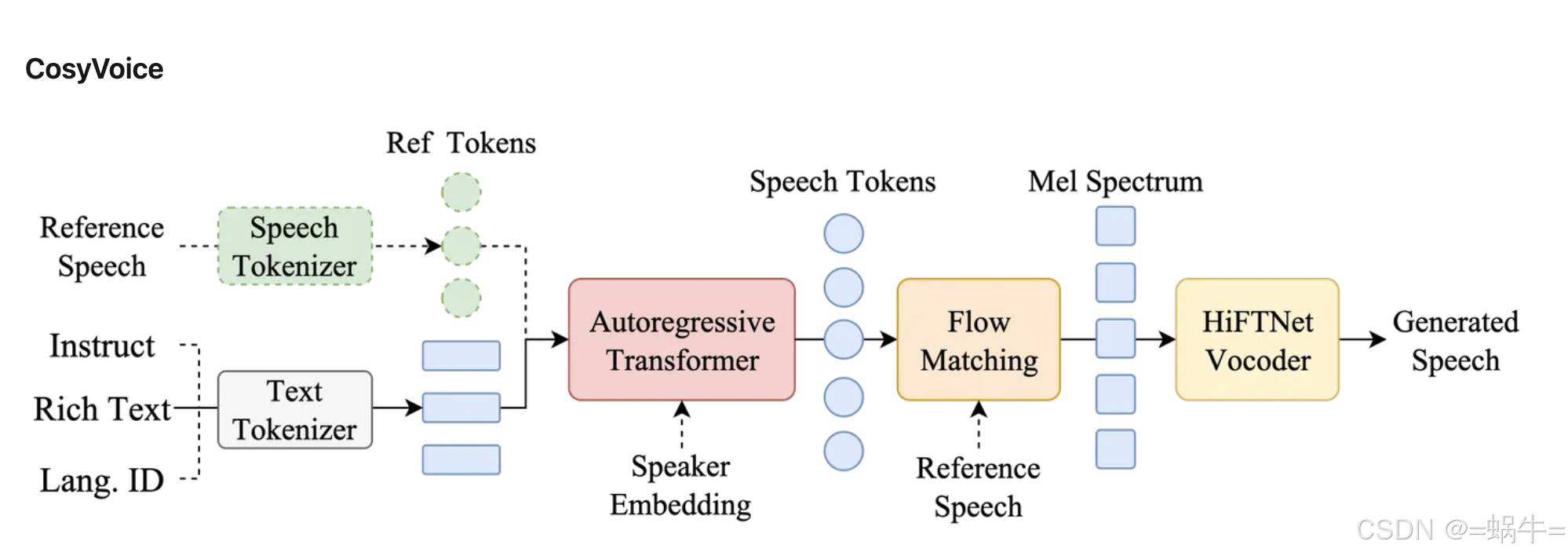
CosyVoice 由一个自回归变换器(用于为输入文本生成相应的语音标记)、一个基于 ODE 的扩散模型、流匹配(用于从生成的语音标记重建梅尔频谱)和一个基于 HiFTNet 的声码器(用于合成波形)组成。虚线模块在特定模型用途中是可选的,例如跨语言、SFT 推理等。
1.2、CosyVoice2 资源
-
开源仓库:https://github.com/FunAudioLLM/CosyVoice

-
示例地址:https://funaudiollm.github.io/cosyvoice2
-
模型地址:https://modelscope.cn/models/iic/CosyVoice2-0.5B/files
- 在线体验:https://www.modelscope.cn/studios/iic/CosyVoice2-0.5B
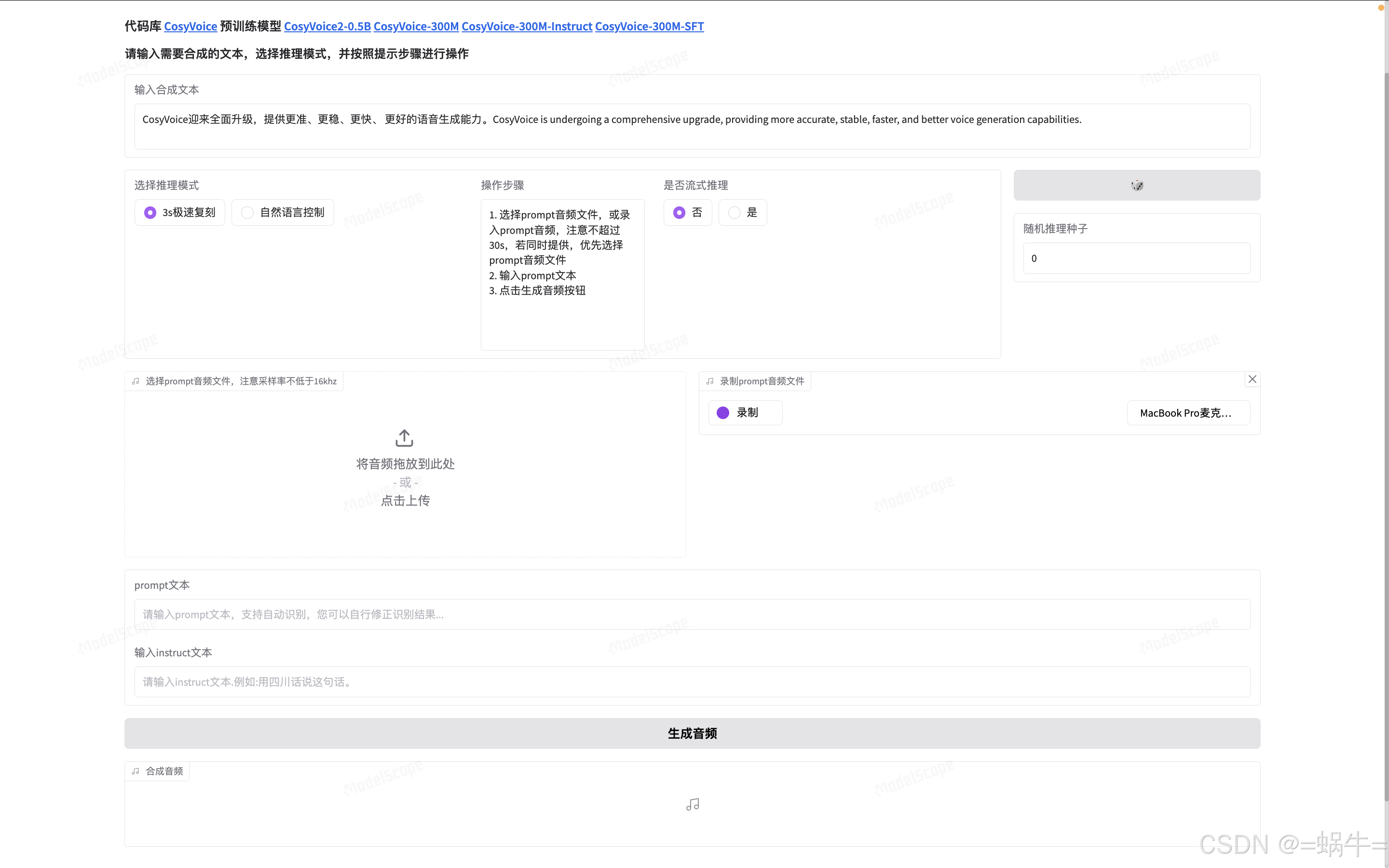
2、安装
2.1、安装 Anaconda
Linux 安装 Anaconda 参考文章
MAC 安装 Anaconda 参考文章
Windows 安装 Anaconda 参考文章
2.2、创建独立环境
# 创建一个名为 wn_cosyvoice 的环境,并指定在该