AI大模型应用之评测篇

在看到公司对于AI 工程师 的岗位要求 :“能够熟练使用各种自动化评测工具与方法,对AI 模型的输出进行有效评估” 时,其实比较疑惑,这个是对大模型能力例如像Deepseek ,GPT-4 ,千问,LLAMA这些模型的能力评测,还是对Agent 类应用结合实际业务的应用输出能力的评测,带着这个问题探寻一下,大概感觉是包含这两者,评测应该是一个泛指的概念,针对AI 领域相关的应用落地效果的评估。
1. 什么是大模型的评测技术
看下Deepseek怎么说 ?

感觉DeepSeek给出了比较官方的阐述:
AI 领域的评测是指通过系统化的方法和工具对人工智能技术的性能,可靠性,适用性及伦理性进行全面评估的过程,其核心目标是验证AI 在不同场景下的实际效果,确保其技术价值与社会需求相匹配。
感觉其实就是回到开篇所说的,评测其实涉及了多个方面:技术性能,硬件评测,应用场景评测,伦理与安全评测等。在网上搜索了一轮和跟着deepseek学习了一轮后,发现了flageval,openCompass 这两个比较专业的评测平台,其实关于大模型评测相关的内容可以在这两个网站上看到比较专业全面的内容。
2. 评测框架
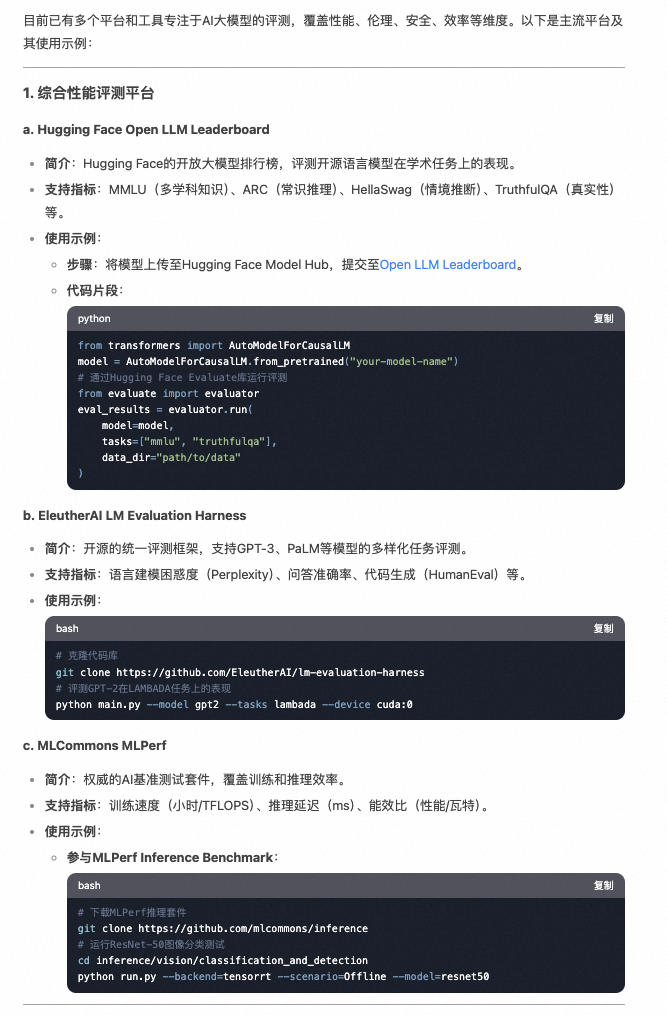
市面上对于AI 大模型评估的平台涉及了性能,伦理,安全,效率等维度,常见的平台有下面这些,看起来有些没有UI 页面的,还是要使用python 写脚来进行评测。 不同的评测需求选择的评测平台各不一样,评测的选型也不一样。
deepseek给出的关于评测的选型:
- 研究需求:学术研究优先选择开源工具(如LM Evaluation Harness),企业需合规报告则选Scale AI。
- 任务类型:
-
- NLP:Hugging Face Leaderboard、OpenAI Evals。
- 多模态:VALSE、MMBench。
- 代码生成:HumanEval、CodeX。
- 资源限制:本地部署用EleutherAI工具,云端评测用W&B或SaaS服务。



3. 大模型评测工具实践
3.1. EleutherAI 综合评测
EleutherAI LM Evaluation Harness 开源的统一评价框架,支持对GPT、T5、BERT等模型在语言理解,推理,知识检索等任务上的标准化评估。
开源链接:
GitHub - EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models.
1、环境准备:
# 创建虚拟环境
conda create -n eval-harness python=3.9
conda activate eval-harness# 安装核心库
pip install lm-eval==0.4.0
pip install torch transformers# 命令行执行
lm-eval \--model hf-causal \--model_args pretrained=EleutherAI/gpt-j-6B \--tasks lambada \--device cuda:0 \--batch_size 16# 输出示例
| lambada | Accuracy | 68.5% | #准确率
| | Perplexity | 12.3 | #模型疑惑度,越低越好,说明模型对提问的意外程度 在本地mac 部署的过程中,pip install lm-eval==0.4.0,安装依赖总是装不成功,公司电脑又有软件安装限制,最终没有跑成功~
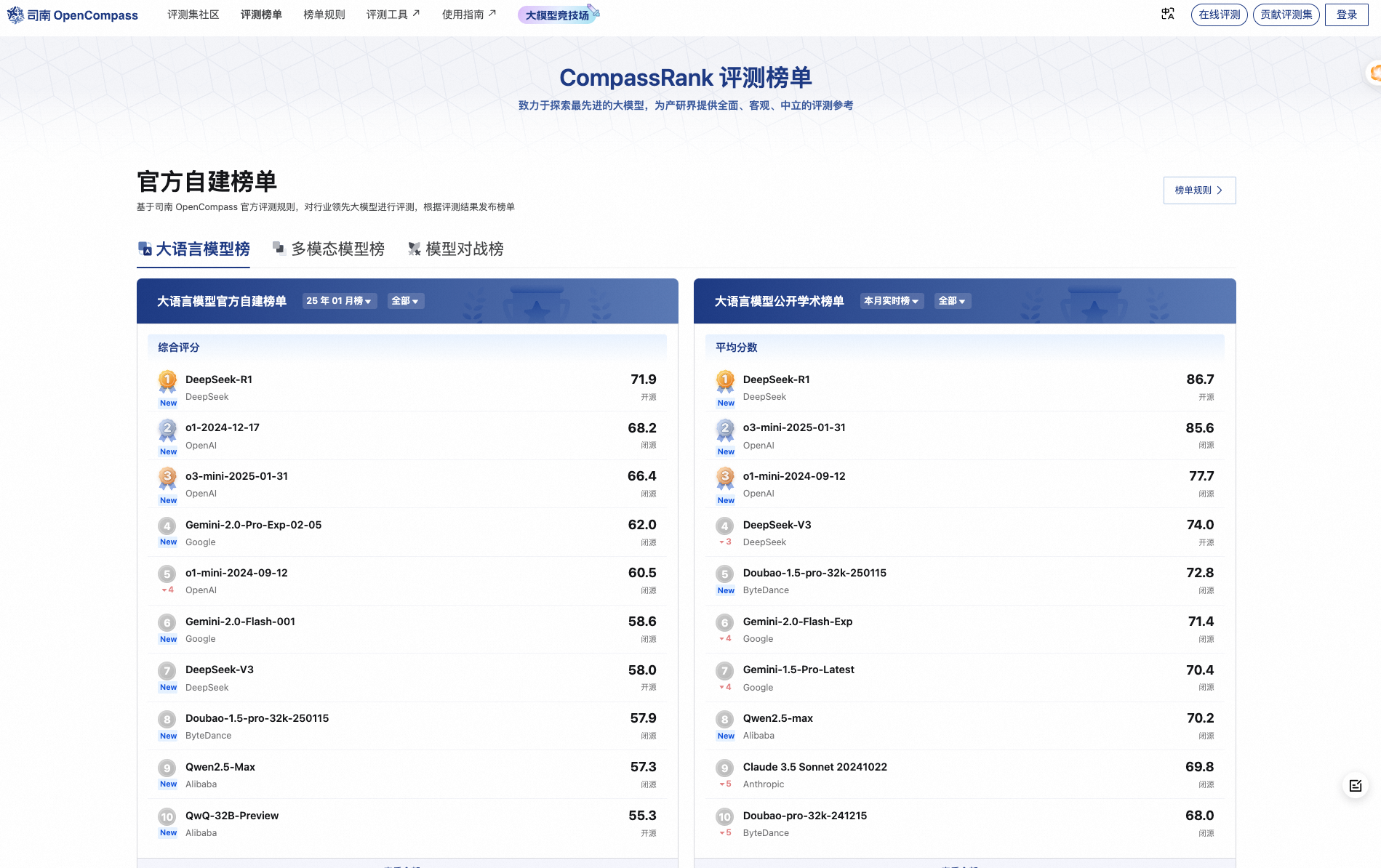
3.2. OpenCompass
主页 :OpenCompass司南
OpenCompass 上海AI Lab开发的大模型评测平台,这个社区里面还是有很多个各种维度的评测工具合集,还是蛮全的。 分了几大类的排行,deepseek还是遥遥领先呀,还有多模态的和对战邦兴
openCompass 使用文档:
安装 — OpenCompass 0.4.2 documentation
可以自己本地运行命令 ,也可以直接平台运行评测任务,还是蛮方便的。

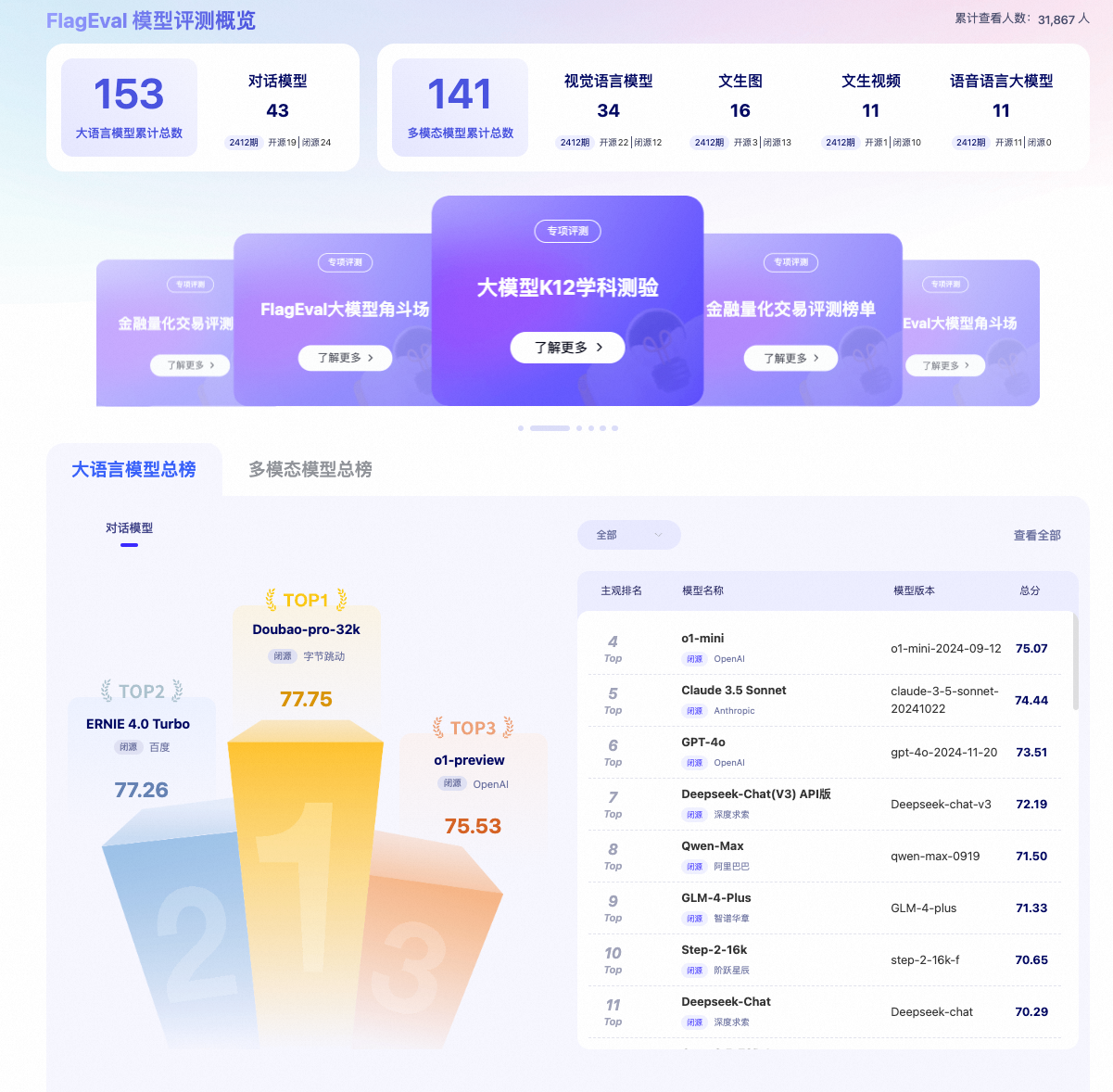
3.3. FlagEval
主页: FlagEval
国内的评测平台 ,涉及到了自然语言处理(NLP) ,多模态(MultiModal) , 计算机视觉(CV), 语音(Audio)四大评测领域
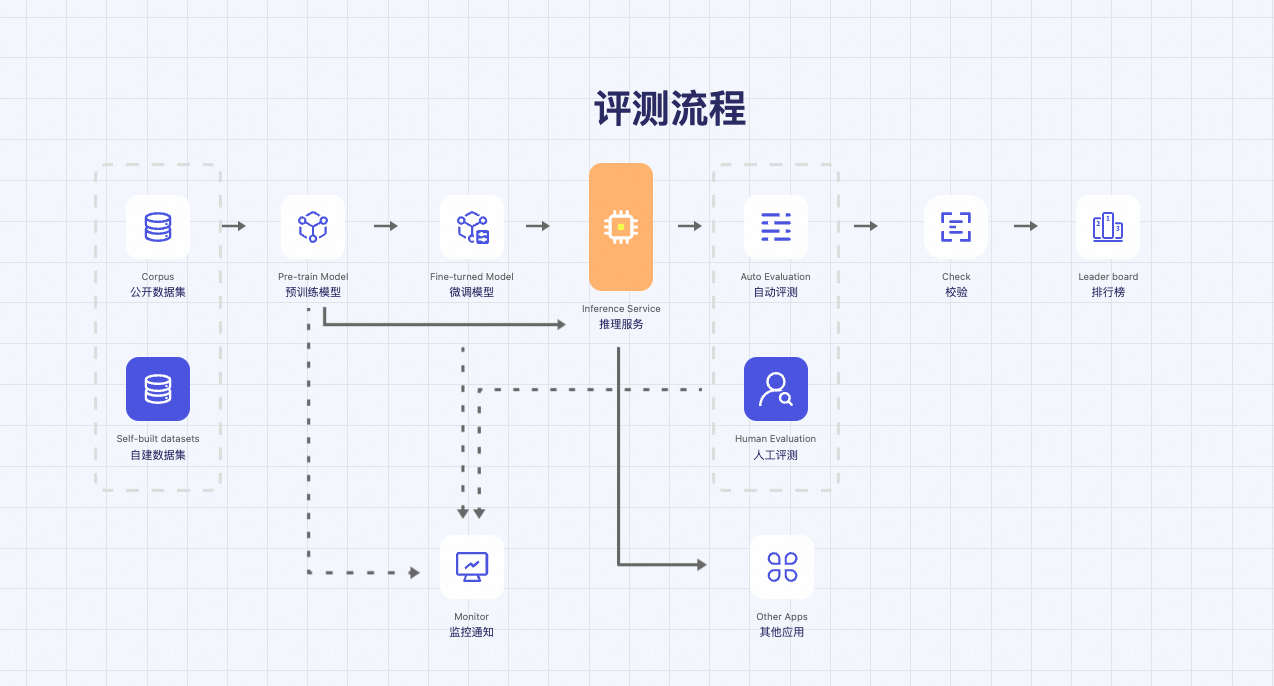
评测流程:
4. 大模型评测基准
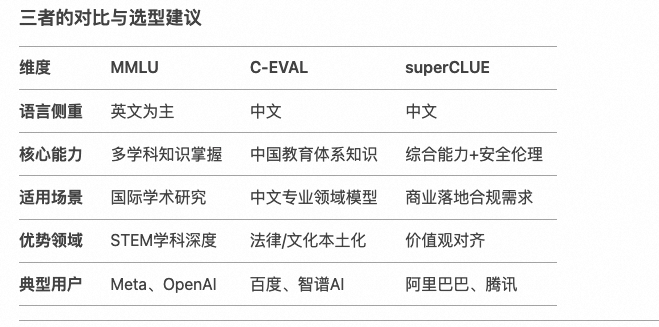
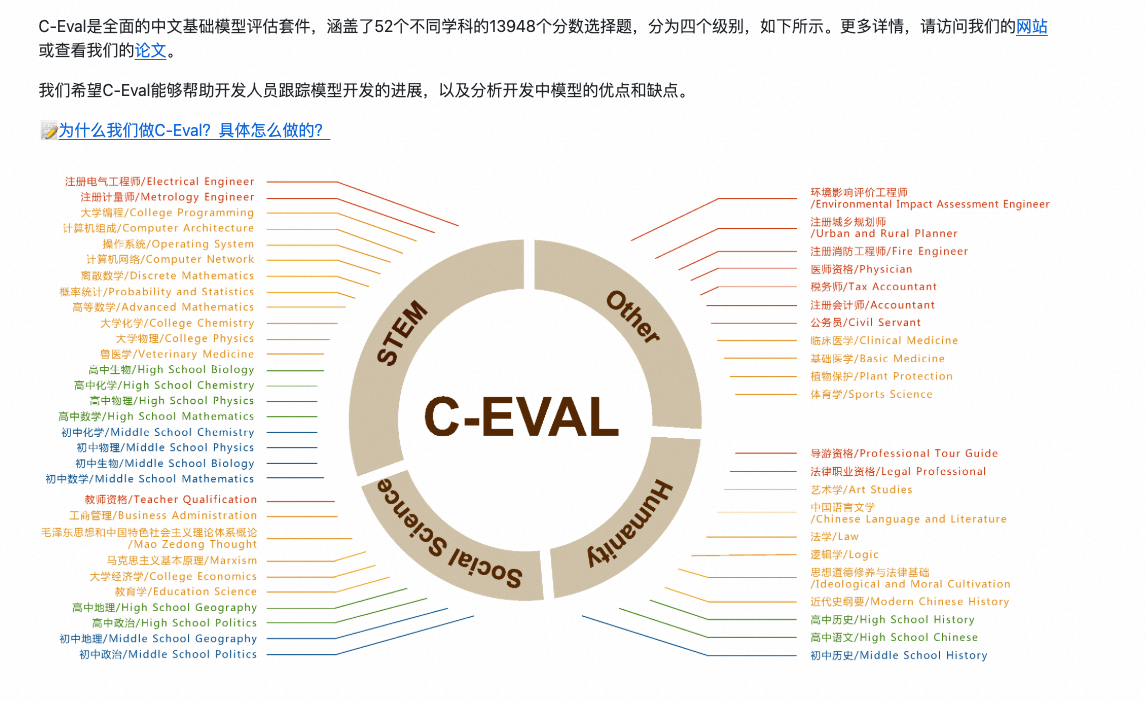
常见的大模型平常指标有MMLU(Massive Multitask Language Understanding) ,C-EVAL (Chinese Evaluation Benchmark) ,superCLUE (Super Chinese Language Understanding Evaluation) ,这些其实是一些测评的数据集。
三者的对比与选型,区分有中英文理解。

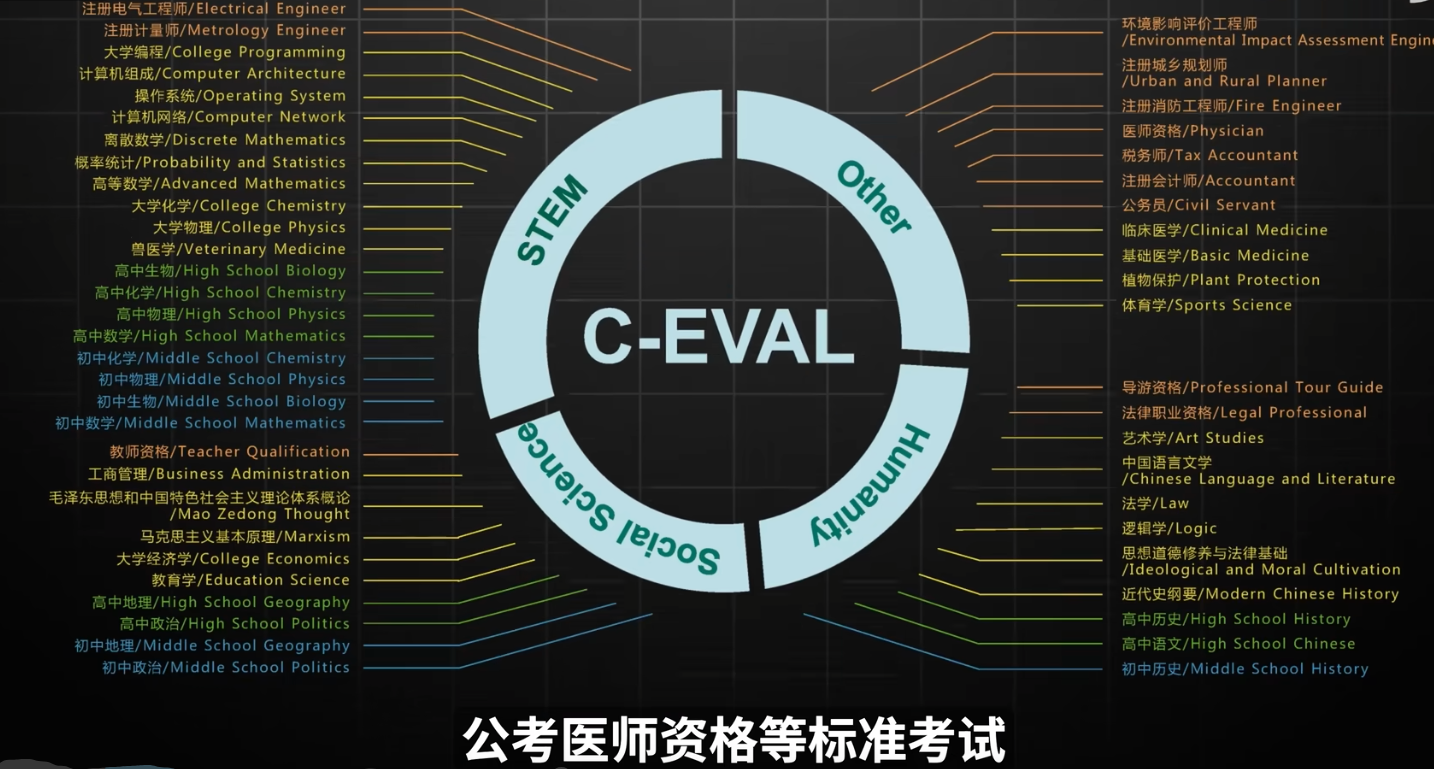

CMMLU评测代码:GitHub - haonan-li/CMMLU: CMMLU: Measuring massive multitask language understanding in Chinese

C-Eval评测代码:GitHub - hkust-nlp/ceval: Official github repo for C-Eval, a Chinese evaluation suite for foundation models [NeurIPS 2023]
知乎里面有一个关于评测的数据集的相关的介绍:
https://zhuanlan.zhihu.com/p/658725797
除了上面三者,还有其他一些评测指标:
可能的指标包括:
1. **推理与逻辑**:Big-Bench Hard(BBH)、DROP
2. **伦理与安全**:ToxiGen、RealToxicityPrompts
3. **多模态**:VQA、MMBench
4. **代码生成**:HumanEval、MBPP
5. **效率与资源消耗**:训练吞吐量、推理延迟
6. **语言生成质量**:Perplexity、BLEU、ROUGE
7. **特定任务**:GLUE、SuperGLUE
8. **交互与对话**:Chatbot Arena、DSTC
9. **数学能力**:MATH、GSM8K
10. **真实性与事实性**:TruthfulQA、FACTOR
评测的选型需要结合3-5项核心指标+ 1-2 项垂直领域指标
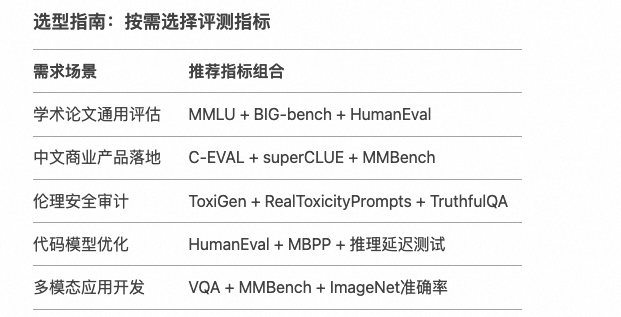
5. 主流大模型评测结果
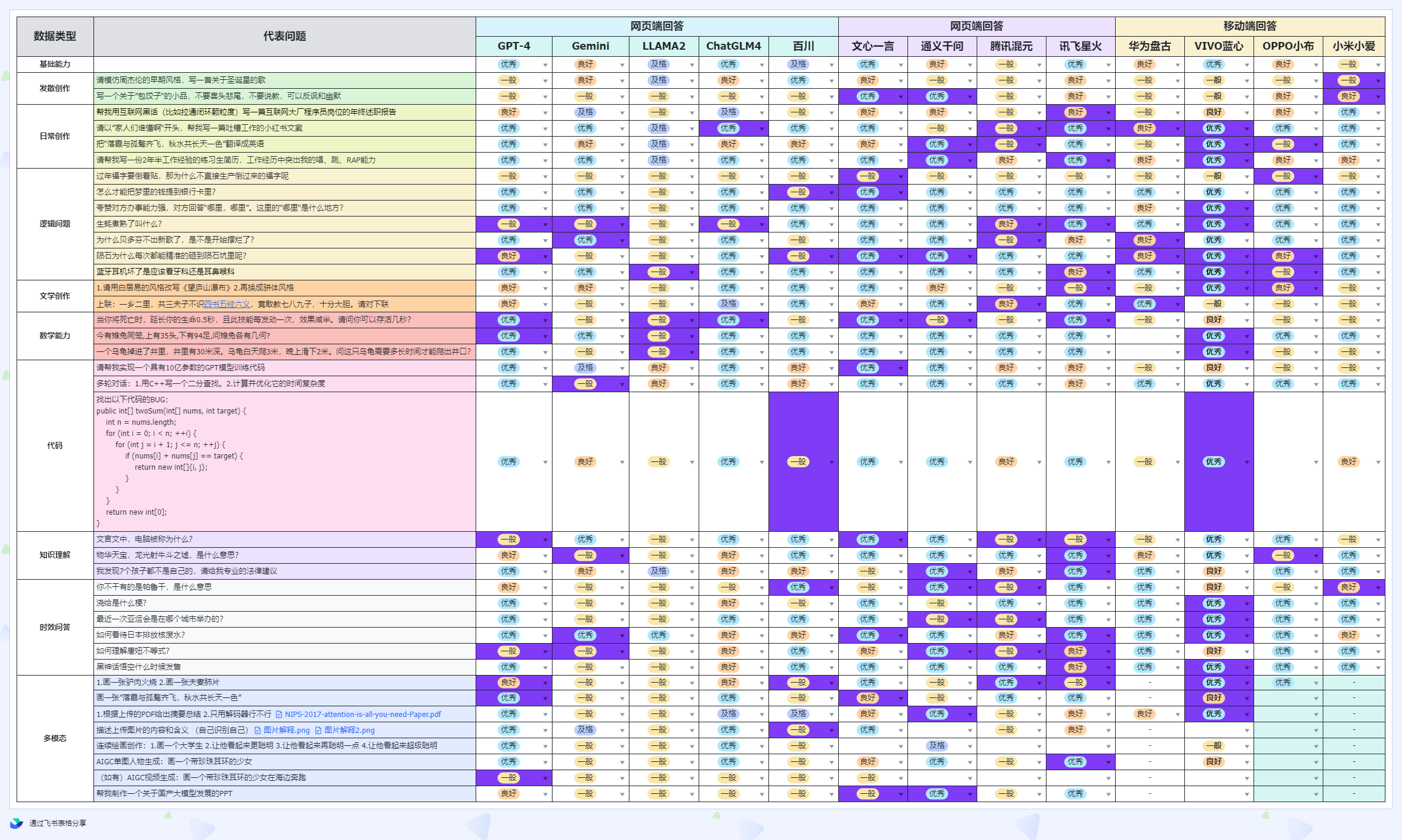
看到b站上有一个播放量最多的对各大模型的评测结果(此时deepseek还没出来),也开源了,从 10个维度进行评测:基础能力,发散创作,日常创作,逻辑问题,文学创作,数据能力,代码,知识理解,时效问题啊,多模态 几大类型进行了一个深度评测,评测结果如下图:
评测的问题:GitHub - Turing-Project/LLMScenarioEval: Scenario-based Evaluation dataset for LLM (beta)
6. 智能体(Agent)评测
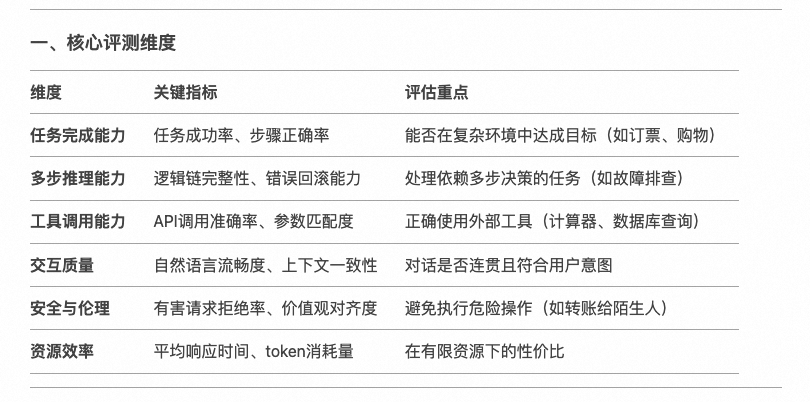
对于基于AI 大模型的智能体(Agent)和大模型的评测又有些许不同,Agent需要结合任务导向性,交互性和环境适应性机芯工评估, 需要在任务完成能力,多步推理能力,工具调用能力,交互质量,安全与伦理,资源效率等多个维度进行评估。评测推荐使用 自然指标(任务成功率)+人工评分(对话自然度)自行进行评估。
评测的工具还是蛮多的,deepseek也给出了很多工具及其详细用法,哎,科技发展进步神速的同事,人的想法,创新能力感觉都要用尽废退了,只要当个执行者就行了,哎,纯当一个不用脑子的执行者其实和人类我思故我在的思想是相悖的,反人性~~此时不免又来灵魂拷问。


7. RAG 系统评测
除去agent 的应用,那些基于RAG的系统评测又需要考虑哪些方面? 这个其实还是要围绕RAG 的几个模块展开,例如检索质量,生成质量,还有就是系统效率和领域适用性。
相关指标如下,主要指标有准确率域与召回率;生成文本与答案相关性(人工或者模型评分),生成内容虚构比例,检索延迟,端到端延迟等。

关于评测的一些基础内容本篇先到这,后面再深入实践一下~