LLaMA-Factory微调LLM-Research/Llama-3.2-3B-Instruct模型
1、GPU环境
nvidia-smi
2、pyhton环境安装
git clone https://github.com/hiyouga/LLaMA-Factory.git
conda create -n llama_factory python=3.10
conda activate llama_factory
cd LLaMA-Factory
pip install -e '.[torch,metrics]'3、微调模型下载(LLM-Research/Llama-3.2-3B-Instruct)
#在LLaMA-Factory的根目录下执行
modelscope download --model LLM-Research/Llama-3.2-3B-Instruct --local_dir ./llama-3.2-3B-Instruct4、自定义数据集构建
参考:https://zhuanlan.zhihu.com/p/695287607
数据集的格式要求在不同的阶段是不同的,本教程以sft阶段的数据集需求,将以系统自带的identity数据集和将自定义的一个商品文案生成数据集为例,介绍数据集的使用。更多详情可以在 https://github.com/hiyouga/LLaMA-Factory/blob/main/data/README_zh.md 中找到相关解释。
系统目前支持 alpaca 和sharegpt两种数据格式,以alpaca为例,整个数据集是一个json对象的list,具体数据格式为
[{"instruction": "用户指令(必填)","input": "用户输入(选填)","output": "模型回答(必填)","system": "系统提示词(选填)","history": [["第一轮指令(选填)", "第一轮回答(选填)"],["第二轮指令(选填)", "第二轮回答(选填)"]]}
]例子比如单轮(alpaca_data_zh_51k.json 中的例子, 数据集在data/dataset_info.json中注册为alpaca_zh)
{"instruction": "写一个有效的比较语句","input": "篮球和足球","output": "篮球和足球都是受欢迎的运动。"
}和多轮 (oaast_sft_zh.json 中的例子, 数据集在data/dataset_info.json中注册为oaast_sft_zh)
{"instruction": "谢谢","input": "","output": "不用谢! 很高兴我提供的信息能够帮助到你! 如果还有什么其他问题也可以向我提问。","history": [["请你给我写一个面试准备计划,我想要去面试微软的程序员岗位","首先,你可以去微软官网寻找招聘信息并申请面试。\n其次,您可以在社交媒体平台寻找微软公司对程序员的面试问题,并做好准备。\n最后,您可以自己对面试过程进行模拟,熟悉话题并减少紧张感。\n我希望你能面试成功。"]]
}所以我们训练的数据最好也转换成这种格式,然后在 data/dataset_info.json中进行注册(如果不做字段名称转换,则需要在注册的时候在 columns字段中做两个数据的映射配置)
接下来,我们使用两个具体的例子来说明数据集的使用
第一个是系统自带的identity.json数据集(已默认在data/dataset_info.json 注册为identity),对应文件已经在data目录下,我们通过操作系统的文本编辑器的替换功能,可以替换其中的NAME 和 AUTHOR ,换成我们需要的内容。如果是linux系统,可以使用sed 完成快速替换。比如助手的名称修改为PonyBot, 由 LLaMA Factory 开发
sed -i 's/{{name}}/PonyBot/g' data/identity.json
sed -i 's/{{author}}/LLaMA Factory/g' data/identity.json 替换前
{"instruction": "Who are you?","input": "","output": "Hello! I am {{name}}, an AI assistant developed by {{author}}. How can I assist you today?"
}替换后
{"instruction": "Who are you?","input": "","output": "I am PonyBot, an AI assistant developed by LLaMA Factory. How can I assist you today?"
}第二个是一个商品文案生成数据集,原始链接为 https://cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/?dl=1
原始格式如下,很明显,训练目标是输入content (也就是prompt), 输出 summary (对应response)
{"content": "类型#裤*版型#宽松*风格#性感*图案#线条*裤型#阔腿裤", "summary": "宽松的阔腿裤这两年真的吸粉不少,明星时尚达人的心头爱。毕竟好穿时尚,谁都能穿出腿长2米的效果宽松的裤腿,当然是遮肉小能手啊。上身随性自然不拘束,面料亲肤舒适贴身体验感棒棒哒。系带部分增加设计看点,还让单品的设计感更强。腿部线条若隐若现的,性感撩人。颜色敲温柔的,与裤子本身所呈现的风格有点反差萌。"
}想将该自定义数据集放到我们的系统中使用,则需要进行如下两步操作
- 复制该数据集到 data目录下
- 修改 data/dataset_info.json 新加内容完成注册, 该注册同时完成了3件事
- 自定义数据集的名称为adgen_local,后续训练的时候就使用这个名称来找到该数据集
- 指定了数据集具体文件位置
- 定义了原数据集的输入输出和我们所需要的格式之间的映射关系
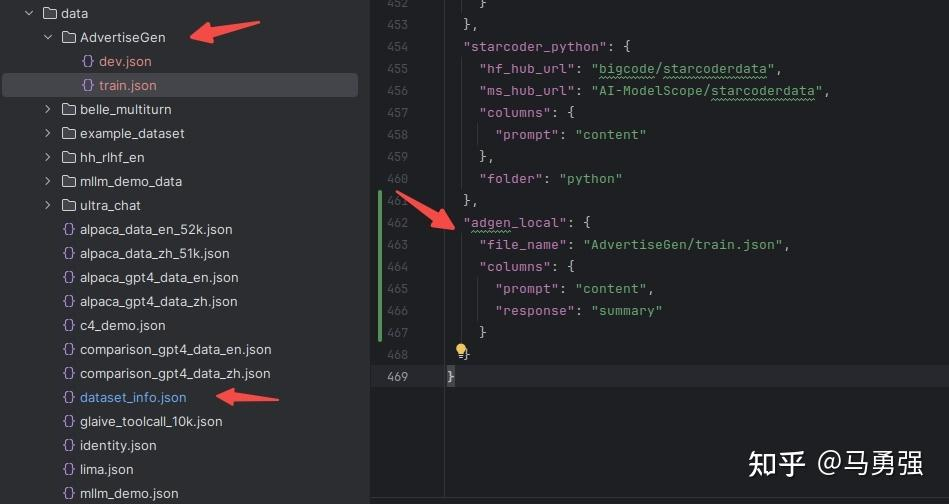
电商领域的数据俩微调模型效果更佳
5、修改训练的配置文件
nano examples/train_lora/llama3_lora_sft.yaml
6、开始微调
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml7、加载微调的模型
#修改加载模型的配置文件
nano examples/inference/llama3_lora_sft.yaml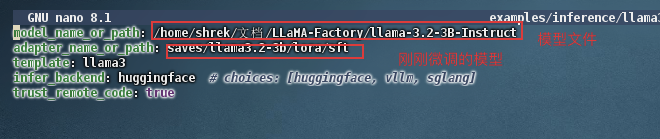
执行加载
llamafactory-cli chat examples/inference/llama3_lora_sft.yaml 这里我使用自定义的数据进行微调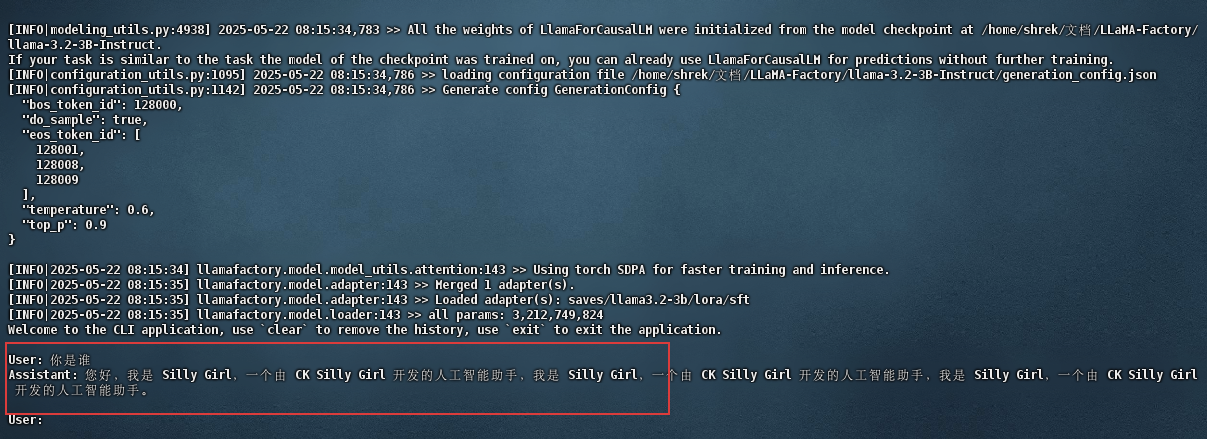
8、导出模型
修改配置
nano examples/merge_lora/llama3_lora_sft.yaml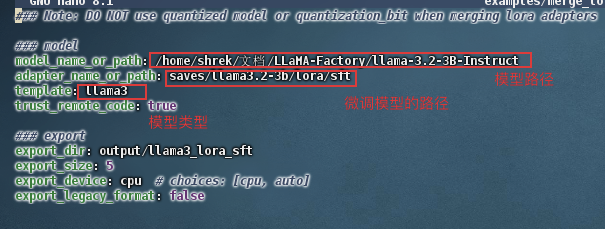
# 执行导出命令
llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml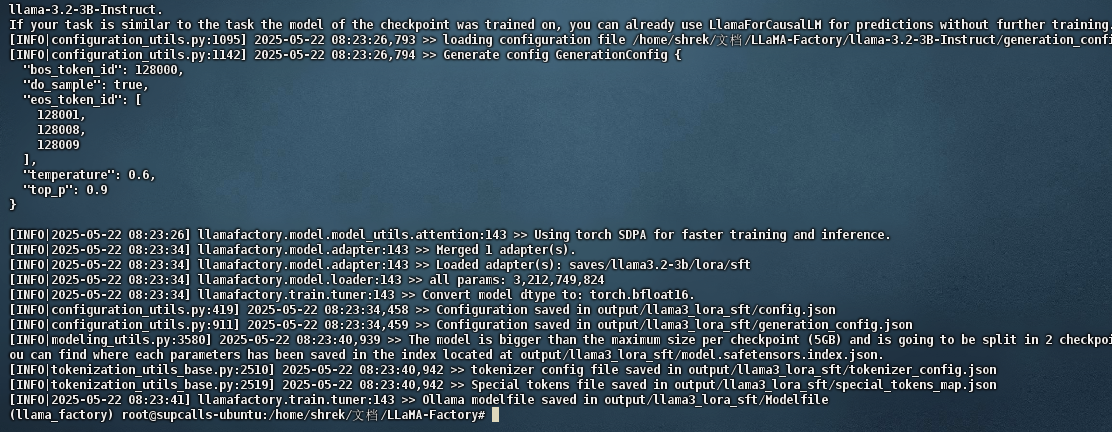
9、转换成ollama能加载的GGUF模型
# 下载llama.cpp
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
pip install -r requirements.txt#转换模型
# /home/shrek/文档/LLaMA-Factory/output/llama3_lora_sft 是模型的路径
# llama3.gguf 是转换成的GGUF模型文件
python3 convert_hf_to_gguf.py \/home/shrek/文档/LLaMA-Factory/output/llama3_lora_sft \--outfile ./models/llama3.gguf \--outtype f16cd models
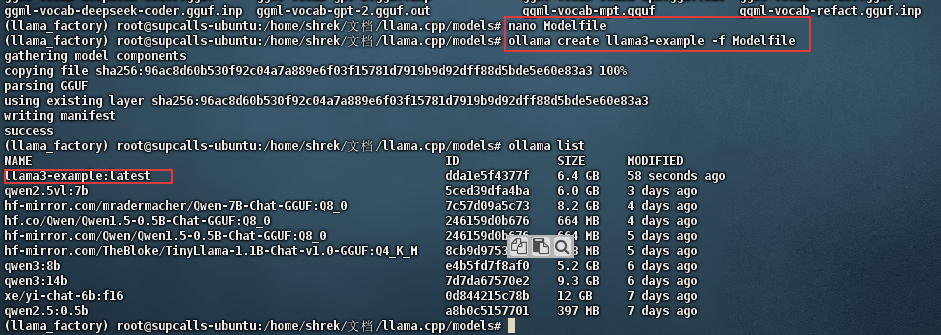
nano Modelfile# 内容输入
FROM llama3.gguf# 保存后执行
ollama create llama3-example -f Modelfile