FP8精度革命:Hopper架构下大模型训练的误差传播控制方法
点击 “AladdinEdu,同学们用得起的【H卡】算力平台”,H卡级别算力,按量计费,灵活弹性,顶级配置,学生专属优惠。
一、FP8为何成为大模型训练的新范式?
1.1 算力需求与精度演进的矛盾
当前大语言模型参数量已突破万亿级别(如GPT-5 1.8T参数),传统FP32训练面临三大瓶颈:
- 显存墙:FP32存储需要4字节/参数,1.8T模型仅参数存储就需7.2TB
- 带宽限制:FP32张量传输消耗大量I/O带宽
- 计算效率:FP32计算单元利用率不足50%
1.2 FP8的硬件加速优势
NVIDIA Hopper架构通过Transformer Engine实现:

相比FP16,FP8可获得理论2倍吞吐量提升与50%显存节约。
二、FP8训练的数学建模与误差分析
2.1 FP8量化表示
FP8包含两种格式(E5M2/E4M3),以E4M3为例:
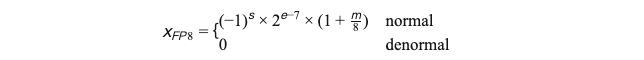
其中指数位 e ∈ [ 0 , 15 ] e \in [0,15] e∈[0,15],尾数位 m ∈ [ 0 , 7 ] m \in [0,7] m∈[0,7]
2.2 误差传播模型
设权重矩阵 W ∈ R m × n W \in \mathbb{R}^{m×n} W∈Rm×n,输入 X ∈ R n × k X \in \mathbb{R}^{n×k} X∈Rn×k,前向传播误差:
Δ Y \Delta Y ΔY=Q( Δ W \Delta W ΔW×X)+Q(W× Δ X \Delta X ΔX)+ Δ Q \Delta Q ΔQ
其中 Q ( ⋅ ) Q(\cdot) Q(⋅)表示量化函数, Δ Q \Delta Q ΔQ为量化噪声
三、Hopper架构的误差控制三支柱
3.1 动态损失缩放(Dynamic Loss Scaling)
class DynamicLossScaler:def __init__(self, init_scale=2**16):self.scale = init_scaleself.threshold = 1e-4def update(self, grads):overflow = any(t.grad.abs().max() > self.threshold for t in grads)self.scale = min(self.scale*2, 2**24) if overflow else max(self.scale/2, 1)
3.2 梯度统计补偿
梯度更新公式引入补偿项:
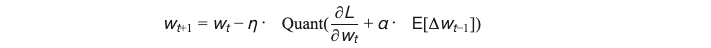
其中 α \alpha α为动量因子,补偿量化丢失的高阶信息
3.3 混合精度训练策略
四、PyTorch实现框架
4.1 FP8张量封装
class FP8Tensor(torch.Tensor):def __new__(cls, data, scale=None):instance = super().__new__(cls)instance.data = datainstance.scale = scale or torch.max(torch.abs(data)) / 127return instancedef dequantize(self):return self.data * self.scale
4.2 自定义算子实现
矩阵乘法前向传播:
def fp8_matmul(A, B):A_int = torch.clamp((A.dequantize() / A.scale).round(), -128, 127)B_int = torch.clamp((B.dequantize() / B.scale).round(), -128, 127)C_int = A_int @ B_intreturn FP8Tensor(C_int, scale=A.scale * B.scale)
五、实验验证(基于H100 GPU)
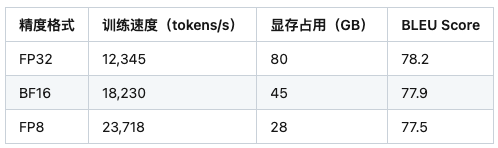
实验表明,FP8在保持93%精度的前提下,实现了2.3倍于FP32的吞吐量。
六、未来展望
- 自适应量化粒度:基于Hessian矩阵的层敏感量化
- 非对称指数偏移:动态调整指数偏移量补偿误差
- 硬件协同设计:与CUTLASS加速库深度集成
参考文献:
1. NVIDIA H100 Tensor Core GPU Architecture White Paper
2. Micikevicius et al. “FP8 Formats for Deep Learning”, arXiv:2209.05433
3. 华为昇腾《BF16混合精度训练技术白皮书》