基于 Zookeeper 部署 Kafka 集群
文章目录
- 1、前期准备
- 2、安装 JDK 8
- 3、搭建 Zookeeper 集群
- 3.1、下载
- 3.2、调整配置
- 3.3、标记节点
- 3.4、启动集群
- 4、搭建 Kafka 集群
- 4.1、下载
- 4.2、调整配置
- 4.3、启动集群
1、前期准备
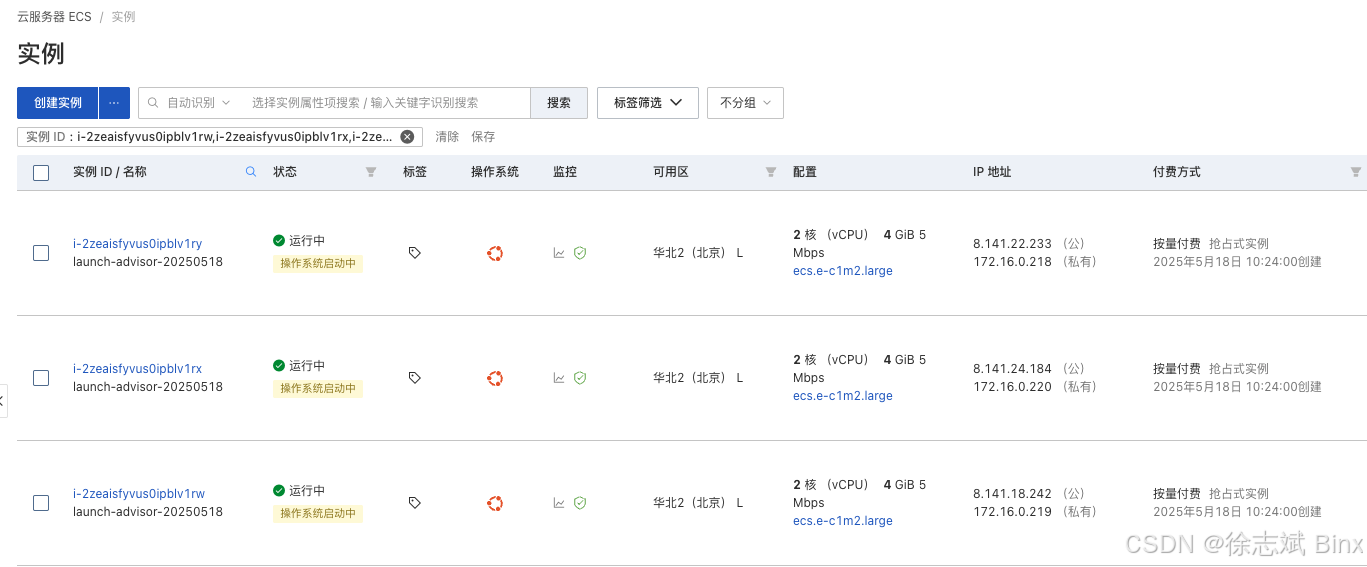
本次集群搭建使用:3 Zookeeper + 3 Kafka,所以我在阿里云租了3台ECS用于本次集群搭建,服务器相关配置如下:
- 操作系统:Ubuntu 22.04
- 配置:2核4G
- 硬盘:40G
- Zookeeper 版本:3.4.14
- Kafka 版本:2.2.0
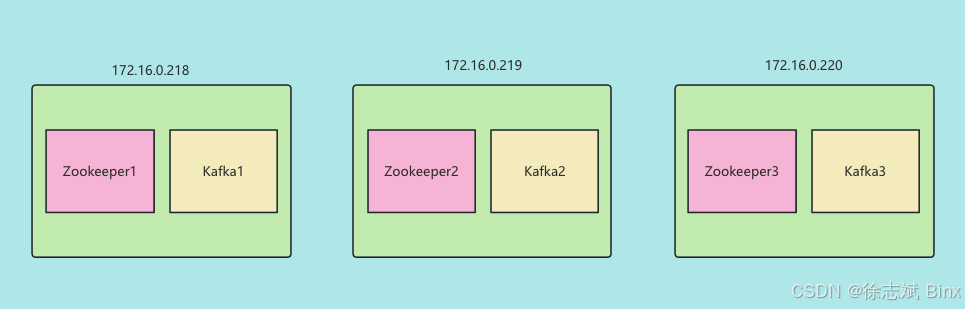
本次部署资源分配如下:
2、安装 JDK 8
在三台服务器上,依次执行下述命令安装好 JDK 8,命令如下:
# 更新库
sudo apt update# 安装 jdk8
sudo apt install openjdk-8-jdk# 配置路径
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export PATH=$JAVA_HOME/bin:$PATH# 保存配置
source ~/.bashrc
3、搭建 Zookeeper 集群
3.1、下载
首先在三台服务器上,依次执行下述命令,先安装好 Zookeeper 3.4.14,命令如下:
# 创建 Zookeeper 安装目录
mkdir /opt/zookeeper
cd /opt/zookeeper# 下载 Zookeeper
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
然后3台服务器上依次进行解压缩操作:
# 解压 Zookeeper
tar -zxvf zookeeper-3.4.14.tar.gz
3.2、调整配置
首先,依次在三台服务器创建目录:
# 存放数据
mkdir /opt/zookeeper/data
# 存放日志
mkdir /opt/zookeeper/log
接着,依次在三台服务器上,将 Zookeeper 文件复制一份,改名为zoo.cfg:
cd /opt/zookeeper/zookeeper-3.4.14/conf/
cp zoo_sample.cfg zoo.cfg
接着调整三台服务器上的 Zookeeper 配置文件zoo.cfg,配置内容一模一样:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/zookeeper/data
dataLogDir=/opt/zookeeper/log
clientPort=2181# Zookeeper集群通信配置
# server.数字:其中数字是/opt/zookeeper/data/myid中的数字
server.1=172.16.0.218:2288:3388
server.2=172.16.0.219:2288:3388
server.3=172.16.0.220:2288:3388
3.3、标记节点
在三台服务器上,依次执行下述命令写入节点标识,Zookeeper 集群通过 myid 文件识别集群节点,并通过zoo_sample.cfg配置的节点通信端口和选举端口来进行节点通信,选举出 leader 节点:
# 服务器1上执行
echo "1" > /opt/zookeeper/data/myid# 服务器2上执行
echo "2" > /opt/zookeeper/data/myid# 服务器3上执行
echo "3" > /opt/zookeeper/data/myid
3.4、启动集群
在三台服务器上,依次启动 Zookeeper 进程:
/opt/zookeeper/zookeeper-3.4.14/bin/zkServer.sh start
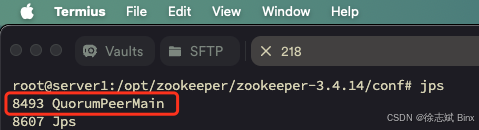
启动完毕后,通过jps命令查看一下 Zookeeper 进程:
通过/opt/zookeeper/zookeeper-3.4.14/bin/zkServer.sh status命令查看当前Zookeeper节点角色:


4、搭建 Kafka 集群
4.1、下载
在三台服务器上都安装 Kafka 2.2.0:
# 创建 Kafka 安装目录
mkdir /opt/kafka
cd /opt/kafka# 下载 Kafka
wget wget https://archive.apache.org/dist/kafka/2.2.0/kafka_2.12-2.2.0.tgz
然后将压缩包进行解压:
# 解压 Kafka
tar -xzf kafka_2.12-2.2.0.tgz
4.2、调整配置
首先,依次在三台服务器创建目录:
# 存放日志
mkdir /opt/kafka/log
接着,修改三台 Kafka 的配置文件server.properties,内容如下:
# 服务器1
broker.id=0
listeners=PLAINTEXT://172.16.0.218:9092
log.dirs=/opt/kafka/log
zookeeper.connect=172.16.0.218:2181,172.16.0.219:2181,172.16.0.220:2181# 服务器2
broker.id=1
listeners=PLAINTEXT://172.16.0.219:9092
log.dirs=/opt/kafka/log
zookeeper.connect=172.16.0.218:2181,172.16.0.219:2181,172.16.0.220:2181# 服务器3
broker.id=2
listeners=PLAINTEXT://172.16.0.220:9092
log.dirs=/opt/kafka/log
zookeeper.connect=172.16.0.218:2181,172.16.0.219:2181,172.16.0.220:2181
4.3、启动集群
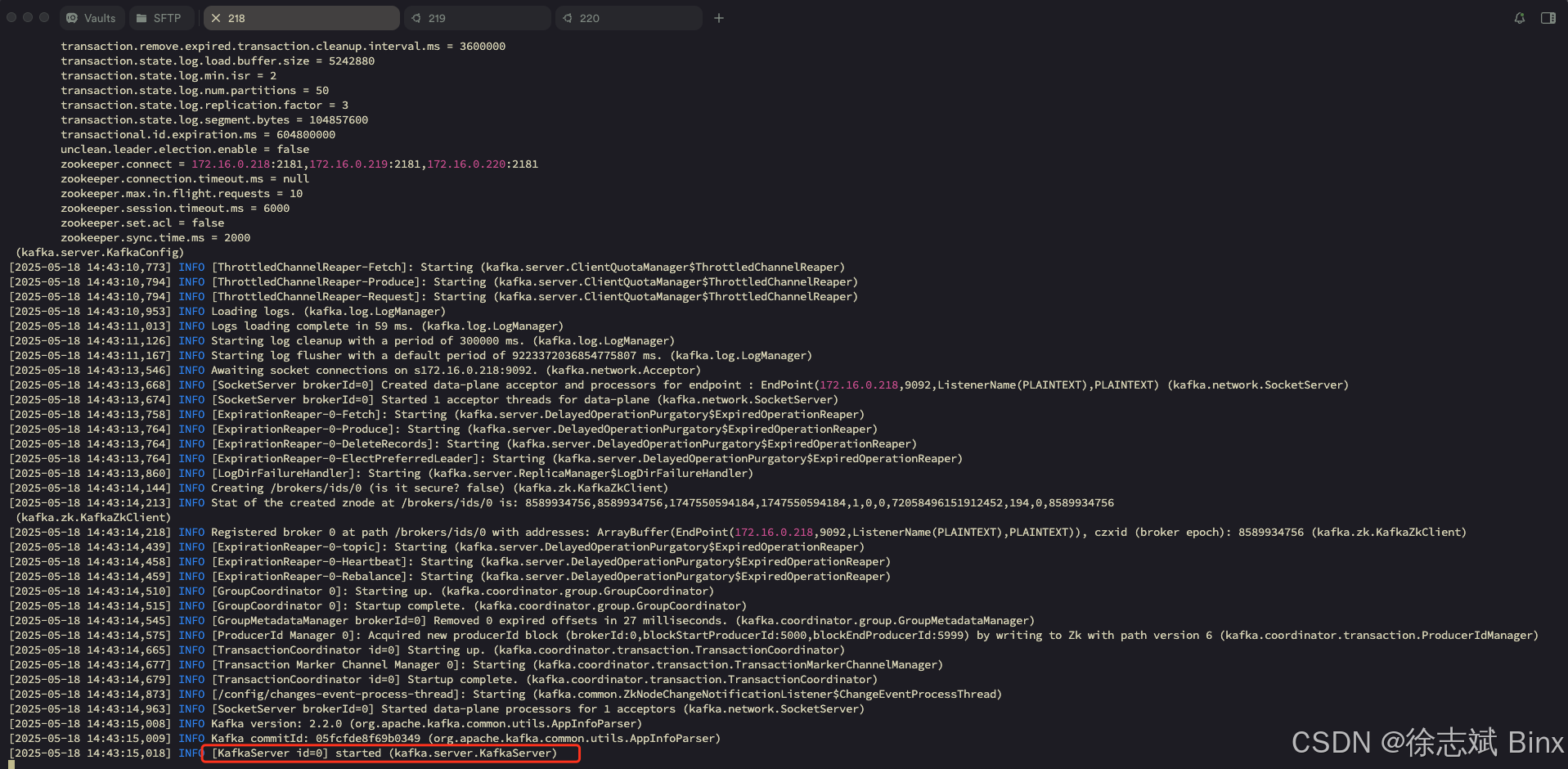
三台服务器上,依次执行下述命令,启动Kafka集群:
cd /opt/kafka/kafka_2.12-2.2.0
bin/kafka-server-start.sh config/server.properties